
CITL Tech Varsity, Bangalore offers 2023 IEEE Projects on Big Data for final year engineering Computer Science & Engineering students (CSE) and Final year engineering projects on Big Data for information science and engineering (ISE) students. Java based 2023 IEEE Projects on for M.Tech, CSE, CNE (Computer Network engineer) and BE CSE, BE ISE students. CITL Tech Varsity, Bangalore also offer online training for projects on Big Data for final year engineering Computer Science & Engineering(CSE) and Final year engineering projects on Big Data for information science and engineering students. CITL offers 2023 IEEE Projects training on software JAVA at very cheap cost. See this section for list of Projects on Big Data or Contact us for details and projects on Big Data.
IEEE 2023 big data (hadoop) project list on java based for mtech / MS / be / btech / mca / M.sc students in Bangalore
CITL Tech varsity offers Big data hadoop based IEEE projects for Mtech and BE final year computer science branch students. Here at CITL, we use apache hadoop i.e., cloudera’s open source platform to work on. It is a java based programming that runs on apache hadoop i.e, on the cloudera framework. We also work on Apache spark big data projects using scar programming We have a technical team who are skilled enough to provide solutions on the latest. IEEE related . Get analytics and hadoop based projects on big data for students using java as core programming language.
Looking for Project Development Guide ? , Join Our Next Batch for End to end Advise from Experts

1.A Micro-video Recommendation System Based on Big Data
With the development of the Internet and social networking service, the micro-video is becoming more popular, especially for youngers. However, for many users, they spend a lot of time to get their favorite micro-videos from amounts videos on the Internet; for the micro-video producers, they do not know what kinds of viewers like their products. Therefore, this paper proposes a micro-video recommendation system. The recommendation algorithms are the core of this system. Traditional recommendation algorithms include content-based recommendation, collaboration recommendation algorithms, and so on. At the Bid Data times, the challenges what we meet are data scale, performance of computing, and other aspects. Thus, this paper improves the traditional recommendation algorithms, using the popular parallel computing framework to process the Big Data. Slope one recommendation algorithm is a parallel computing algorithm based on MapReduce and Hadoop framework which is a high performance parallel computing platform. The other aspect of this system is data visualization. Only an intuitive, accurate visualization interface, the viewers and producers can find what they need through the micro-video recommendation system.
System Architecture
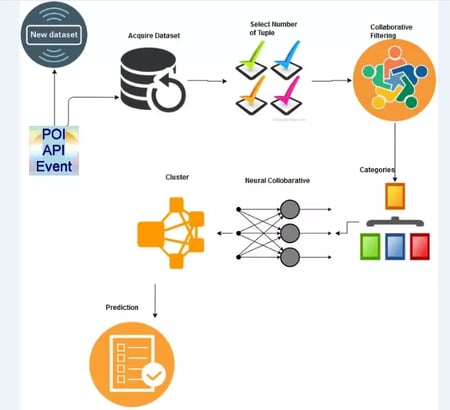
Project Overview
Fetching the users and associated interests youtube videos and recommends the nearest matching video(singer based) with neural network algorithm. Video recommendation with accuracy.
System requirement
Hardware Requirement
Processor - Dual Core
Speed - 1.1 G Hz
RAM - 512 MB (min)
Hard - 20 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Software Requirement Operating System : Windows xp,7,8
Front End : Java 7
Technology : Swings, Core java.
IDE : Netbeans.
2.Map Reduce Programming Model for Parallel K-Medoid Algorithm on Hadoop Cluster
This paper presents result analysis of K-Medoid algorithm, implemented on Hadoop Cluster by using Map-Reduce concept. Map-Reduce are programming models which authorize the managing of huge datasets in parallel, on a large number of devices. It is especially well suited to constant or moderate changing set of data since the implementation point of a position is usually high. MapReduce is supposed to be framework of “big data”.
The MapReduce model authorizes for systematic and instant organizing of large scale data with a cluster of evaluate nodes. One of the primary affect in Hadoop is how to minimize the completion length (i.e., make span) of a set of MapReduce duty. For various applications like word count, grep, terasort and parallel K-Medoid Clustering Algorithm, it has been observed that as the number of node increases, execution time decreases. In this paper we verified Map Reduce applications and found as the amount of nodes increases the completion time decreases.
3.Logic Bug Detection and Localization Using Symbolic Quick Error Detection
We present Symbolic Quick Error Detection (Symbolic QED), a structured approach for logic bug detection and localization which can be used both during pre-silicon design verification as well as post-silicon validation and debug. This new methodology leverages prior work on Quick Error Detection (QED) which has been demonstrated to drastically reduce the latency, in terms of the number of clock cycles, of error detection following the activation of a logic (or electrical) bug. QED works through software transformations, including redundant execution and control flow checking, of the applied tests.
Symbolic QED combines these error detecting QED transformations with bounded model checking-based formal analysis to generate minimal-length bug activation traces that detect and localize any logic bugs in the design. We demonstrate the practicality and effectiveness of Symbolic QED using the Open SPARC T2, a 500-million-transistor open-source multicore System-on-Chip (SoC) design, and using "difficult" logic bug scenarios observed in various state-of-the-art commercial multicore SoCs.
Our results show that Symbolic QED: (i) is fully automatic, unlike manual techniques in use today that can be extremely time-consuming and expensive; (ii) requires only a few hours in contrast to manual approaches that might take days (or even months) or formal techniques that often take days or fail completely for large designs; and (iii) generates counter-examples (for activating and detecting logic bugs) that are up to 6 orders of magnitude shorter than those produced by traditional techniques. Significantly, this new approach does not require any additional hardware.
4.Cloud Centric Authentication for Wearable Healthcare Monitoring System
Security and privacy are the major concerns in cloud computing as users have limited access on the stored data at the remote locations managed by different service providers.
These become more challenging especially for the data generated from the wearable devices as it is highly sensitive and heterogeneous in nature. Most of the existing techniques reported in the literature are having high computation and communication costs and are vulnerable to various known attacks, which reduce their importance for applicability in real-world environment.
Hence, in this paper, we propose a new cloud based user authentication scheme for secure authentication of medical data. After successful mutual authentication between a user and wearable sensor node, both establish a secret session key that is used for future secure communications. The extensively-used Real-Or-Random (ROR) model based formal security analysis and the broadly-accepted Automated Validation of Internet Security Protocols and Applications (AVISPA) tool based formal security verification show that the proposed scheme provides the session-key security and protects active attacks.
The proposed scheme is also informally analyzed to show its resilience against other known attacks. Moreover, we have done a detailed comparative analysis for the communication and computation costs along with security and functionality features which proves its efficiency in comparison to the other existing schemes of its category
5.Big Data Analytics:Predicting Academic Course Preference Using Hadoop Inspired MapReduce
With the emergence of new technologies, new academic trends introduced into Educational system which results in large data which is unregulated and it is also challenge for students to prefer to those academic courses which are helpful in their industrial training and increases their career prospects. Another challenge is to convert the unregulated data into structured and meaningful information there is need of Data Mining Tools. Hadoop Distributed File System is used to hold large amount of data.
The Files are stored in a redundant fashion across multiple machines which ensure their endurance to failure and parallel applications. Knowledge extracted using Map Reduce will be helpful in decision making for students to determine courses chosen for industrial trainings. In this paper, we are deriving preferable courses for pursuing training for students based on course combinations. Here, using HDFS, tasks run over Map Reduce and output is obtained after aggregation of results.
6.Enabling Efficient User Revocation in Identity-based Cloud Storage Auditing for Shared Big Data
Cloud storage auditing schemes for shared data refer to checking the integrity of cloud data shared by a group of users. User revocation is commonly supported in such schemes, as users may be subject to group membership changes for various reasons. Previously, the computational overhead for user revocation in such schemes is linear with the total number of file blocks possessed by a revoked user.
The overhead, however, may become a heavy burden because of the sheer amount of the shared cloud data. Thus, how to reduce the computational overhead caused by user revocations becomes a key research challenge for achieving practical cloud data auditing. In this paper, we propose a novel storage auditing scheme that achieves highly-efficient user revocation independent of the total number of file blocks possessed by the revoked user in the cloud. This is achieved by exploring a novel strategy for key generation and a new private key update technique.
Using this strategy and the technique, we realize user revocation by just updating the non revoked group users’ private keys rather than authenticators of the revoked user. The integrity auditing of the revoked user’s data can still be correctly performed when the authenticators are not updated. Meanwhile, the proposed scheme is based on identity-base cryptography, which eliminates the complicated certificate management in traditional Public Key Infrastructure (PKI) systems. The security and efficiency of the proposed scheme are validated via both analysis and experimental results.
7.Smart Governance through Big Data: Digital Transformation of Public Agencies
Bigdata is a potential instrument to transform traditional governance into smart governance. There are a long debate and discussion on the application of big data for the transformation of traditional public administration to modern and smart public administration in the academician, researchers, and policymakers. This study aims to explore the suitability and applicability of big data for smart governance of public agencies.
A systematic review of literature and meta analysis method is employed with various levels of scales and indicators. Literature survey shows that a number of models have been developed to explain smart governance but systematic research on the suitability and applicability of big data for smart governance of public agencies is still lacking. This article argues that the application of big data for smart governance in the public sector can increase the efficiency of the public agencies fastest public service delivery, enhancing transparency, reducing public hassle and helping to the become a smart agency.
This paper further argues that implementation of big data for smart governance has a significant role in timely, error-free, appropriate and cost effective service delivery to citizens which leads to the sustainable economic development of a country. The findings suggest that every public-sector agency should be brought under smart governance which should be a fully promoted under big data technologies for easy access, transparent and accountable, and hassle-free public agencies.
8.Big Data Analytics:Predicting Academic Course Preference Using Hadoop Inspired MapReduce
With the emergence of new technologies, new academic trends introduced into Educational system which results in large data which is unregulated and it is also challenge for students to prefer to those academic courses which are helpful in their industrial training and increases their career prospects. Another challenge is to convert the unregulated data into structured and meaningful information there is need of Data Mining Tools. Hadoop Distributed File System is used to hold large amount of data.
The Files are stored in a redundant fashion across multiple machines which ensure their endurance to failure and parallel applications. Knowledge extracted using Map Reduce will be helpful in decision making for students to determine courses chosen for industrial trainings. In this paper, we are deriving preferable courses for pursuing training for students based on course combinations. Here, using HDFS, tasks run over Map Reduce and output is obtained after aggregation of results.
9.Map Reduce Programming Model for Parallel K-Mediod Algorithm on Hadoop Cluster
This paper presents result analysis of K-Medoid algorithm, implemented on Hadoop Cluster by using Map-Reduce concept. Map-Reduce are programming models which authorize the managing of huge datasets in parallel, on a large number of devices. It is especially well suited to constant or moderate changing set of data since the implementation point of a position is usually high. MapReduce is supposed to be framework of “big data”.
The MapReduce model authorizes for systematic and instant organizing of large scale data with a cluster of evaluate nodes. One of the primary affect in Hadoop is how to minimize the completion length (i.e., make span) of a set of MapReduce duty. For various applications like word count, grep, terasort and parallel K-Medoid Clustering Algorithm, it has been observed that as the number of node increases, execution time decreases. In this paper we verified Map Reduce applications and found as the amount of nodes increases the completion time decreases.
10.Logic Bug Detection and Localization Using Symbolic Quick Error Detection
We present Symbolic Quick Error Detection (Symbolic QED), a structured approach for logic bug detection and localization which can be used both during pre-silicon design verification as well as post-silicon validation and debug. This new methodology leverages prior work on Quick Error Detection (QED) which has been demonstrated to drastically reduce the latency, in terms of the number of clock cycles, of error detection following the activation of a logic (or electrical) bug. QED works through software transformations, including redundant execution and control flow checking, of the applied tests.
Symbolic QED combines these error detecting QED transformations with bounded model checking-based formal analysis to generate minimal-length bug activation traces that detect and localize any logic bugs in the design. We demonstrate the practicality and effectiveness of Symbolic QED using the OpenSPARC T2, a 500-million-transistor open-source multicore System-on-Chip (SoC) design, and using "difficult" logic bug scenarios observed in various state-of-the-art commercial multicore SoCs.
Our results show that Symbolic QED: (i) is fully automatic, unlike manual techniques in use today that can be extremely time-consuming and expensive; (ii) requires only a few hours in contrast to manual approaches that might take days (or even months) or formal techniques that often take days or fail completely for large designs; and (iii) generates counter-examples (for activating and detecting logic bugs) that are up to 6 orders of magnitude shorter than those produced by traditional techniques. Significantly, this new approach does not require any additional hardware.
11.Enabling Efficient User Revocation in Identity-based Cloud Storage Auditing for Shared Big Data
Cloud storage auditing schemes for shared data refer to checking the integrity of cloud data shared by a group of users. User revocation is commonly supported in such schemes, as users may be subject to group membership changes for various reasons. Previously, the computational overhead for user revocation in such schemes is linear with the total number of file blocks possessed by a revoked user. The overhead, however, may become a heavy burden because of the sheer amount of the shared cloud data.
Thus, how to reduce the computational overhead caused by user revocations becomes a key research challenge for achieving practical cloud data auditing. In this paper, we propose a novel storage auditing scheme that achieves highly-efficient user revocation independent of the total number of file blocks possessed by the revoked user in the cloud. This is achieved by exploring a novel strategy for key generation and a new private key update technique.
Using this strategy and the technique, we realize user revocation by just updating the non revoked group users’ private keys rather than authenticators of the revoked user. The integrity auditing of the revoked user’s data can still be correctly performed when the authenticators are not updated. Meanwhile, the proposed scheme is based on identity-base cryptography, which eliminates the complicated certificate management in traditional Public Key Infrastructure (PKI) systems. The security and efficiency of the proposed scheme are validated via both analysis and experimental results.
12.Twitter data analysis and visualizations using the R language on top of the Hadoop platform
The main objective of the work presented within this paper was to design and implement the system for twitter data analysis and visualization in R environment using the big data processing technologies. Our focus was to leverage existing big data processing frameworks with its storage and computational capabilities to support the analytical functions implemented in R language.
We decided to build the backend on top of the Apache Hadoop framework including the Hadoop HDFS as a distributed filesystem and MapReduce as a distributed computation paradigm. RHadoop packages were then used to connect the R environment to the processing layer and to design and implement the analytical functions in a distributed manner. Visualizations were implemented on top of the solution as a RShiny application.
13.QoS-Aware Data Replications and Placements for Query Evaluation of Big Data Analytics
Enterprise users at different geographic locations generate large-volume data and store their data at different geographic datacenters. These users may also issue ad hoc queries of big data analytics on the stored data to identify valuable information in order to help them make strategic decisions. However, it is well known that querying such large-volume big data usually is time-consuming and costly. Sometimes, users are only interested in timely approximate rather than exact query results.
When this approximation is the case, applications must sacrifice either timeliness or accuracy by allowing either the latency of delivering more accurate results or the accuracy error of delivered results based on the samples of the data, rather than the entire set of data itself. In this paper, we study the Qo Saware data replications and placements for approximate query evaluation of big data analytics in a distributed cloud, where the original (source) data of a query is distributed at different geo-distributed datacenters.
We focus on placing the samples of the source data with certain error bounds at some strategic datacenters to meet users’ stringent query response time. We propose an efficient algorithm for evaluating a set of big data analytic queries with the aim to minimize the evaluation cost of the queries while meeting their response time requirements. We demonstrate the effectiveness of the proposed algorithm through experimental simulations. Experimental results show that the proposed algorithm is promising.
14.Traffic-aware Task Placement with Guaranteed Job Completion Time for Geo-distributed Big Data
Big data analysis is usually casted into parallel jobs running on geo-distributed data centers. Different from a single data center, geo-distributed environment imposes big challenges for big data analytics due to the limited network bandwidth between data centers located in different regions.Although research efforts have been devoted to geo-distributed big data, the results are still far from being efficient because of their suboptimal performance or high complexity.
In this paper, we propose a traffic-aware task placement to minimize job completion time of big data jobs. We formulate the problem as a non-convex optimization problem and design an algorithm to solve it with proved performance gap. Finally, extensive simulations are conducted to evaluate the performance of our proposal. The simulation results show that our algorithm can reduce job completion time by 40%, compared to a conventional approach that aggregates all data for centralized processing. Meanwhile, it has only 10% performance gap with the optimal solution, but its problem-solving time is extremely small.
15.Online Data Deduplication for In-Memory Big-Data Analytic Systems
Given a set of files that show a certain degree of similarity, we consider a novel problem of performing data redundancy elimination across a set of distributed worker nodes in a shared-nothing in-memory big data analytic system. The redundancy elimination scheme is designed in a manner that is: (i) space-efficient: the total space needed to store the files is minimized and, (ii) access-isolation: data shuffling among server is also minimized.
In this paper, we first show that finding an access-efficient and space optimal solution is an NP-Hard problem. Following this, we present the file partitioning algorithms that locate access-efficient solutions in an incremental manner with minimal algorithm time complexity (polynomial time). Our experimental verification on multiple data sets confirms that the proposed file partitioning solution is able to achieve compression ratio close to the optimal compression performance achieved by a centralized solution.
16.Novel Common Vehicle Information Model (CVIM) for Future Automotive Vehicle Big Data Marketplaces
Even though connectivity services have been introduced in many of the most recent car models, access to vehicle data is currently limited due to its proprietary nature. The European project AutoMat has therefore developed an open Marketplace providing a single point of access for brand independent vehicle data. Thereby, vehicle sensor data can be leveraged for the design and implementation of entirely new services even beyond traffic-related applications (such as hyperlocal traffic forecasts).
This paper presents the architecture for a Vehicle Big Data Marketplace as enabler of cross-sectorial and innovative vehicle data services. Therefore, the novel Common Vehicle Information Model (CVIM) is defined as an open and harmonized data model, allowing the aggregation of brand independent and generic data sets. Within this work the realization of a prototype CVIM and Marketplace implementation is presented. The two use-cases of local weather prediction and road quality measurements are introduced to show the applicability of the AutoMat concept and prototype to nonautomotive applications.
17.Holistic Perspective of Big Data in Healthcare
Healthcare has increased its overall value by adopting big data methods to analyze and understand its data from various sources. This article presents big data from the perspective of improving healthcare services and, also, offers a holistic view of system security and factors determining security breaches.
18.Focusing on a Probability Element: Parameter Selection of Message Importance Measure in Big Data
Message importance measure (MIM) is applicable to characterize the importance of information in the scenario of big data, similar to entropy in information theory. In fact, MIM with a variable parameter can make an effect on the characterization of distribution. Furthermore, by choosing an appropriate parameter of MIM, it is possible to emphasize the message importance of a certain probability element in a distribution.
Therefore, parametric MIM can play a vital role in anomaly detection of big data by focusing on probability of an anomalous event. In this paper, we propose a parameter selection method of MIM focusing on a probability element and then present its major properties. In addition, we discuss the parameter selection with prior probability, and investigate the availability in a statistical processing model of big data for anomaly detection problem.
19.CryptMDB: A Practical Encrypted MongoDB over Big Data
In big data era, data are usually stored in databases for easy access and utilization, which are now woven into every aspect of our lives. However, traditional relational databases cannot address users’ demands for quick data access and calculating, since they cannot process data in a distributed way. To tackle this problem, non-relational databases such as MongoDB have emerged up and been applied in various Scenarios. Nevertheless, it should be noted that most MongoDB products fail to consider user’s data privacy.
In this paper, we propose a practical encrypted MongoDB ( i.e., CryptMDB ). Specifically, we utilize an additive homomorphic asymmetric cryptosystem to encrypt user’s data and achieve strong privacy protection. Security analysis indicates that the CryptMDB can achieve confidentiality of user’s data and prevent adversaries from illegally gaining access to the database. Furthermore, extensive experiments demonstrate that the CryptMDB achieves better efficiency than existing relational database in terms of data access and calculating.
20.Cost Aware Cloudlet Placement for Big Data Processing at the Edge
As accessing computing resources from the remote cloud for big data processing inherently incurs high end-to-end (E2E) delay for mobile users, cloudlets, which are deployed at the edge of networks, can potentially mitigate this problem. Although load offloading in cloudlet networks has been proposed, placing the cloudlets to minimize the deployment cost of cloudlet providers and E2E delay of user requests has not been addressed so far.
The locations and number of cloudlets and their servers have a crucial impact on both the deployment cost and E2E delay of user requests. Therefore, in this paper, we propose the Cost Aware cloudlet PlAcement in moBiLe Edge computing strategy (CAPABLE) to optimize the tradeoff between the deployment cost and E2E delay. When cloudlets are already placed in the network, we also design a load allocation scheme to minimize the E2E delay of user requests by assigning the workload of each region to the suitable cloudlets. The performance of CAPABLE is demonstrated by extensive simulation results.
21.Big-Data-Driven Network Partitioning for Ultra-Dense Radio Access Networks
The increased density of base stations (BSs) may significantly add complexity to network management mechanisms and hamper them from efficiently managing the network. In this paper, we propose a big-data-driven network partitioning and optimization framework to reduce the complexity of the networking mechanisms. The proposed framework divides the entire radio access network (RAN) into multiple sub-RANs and each sub-RAN can be managed independently. Therefore, the complexity of the network management can be reduced.Quantifying the relationships among BSs is challenging in the network partitioning. We propose to extract three networking features from mobile traffic data to discover the relationships.
Based on these features, we engineer the network partitioning solution in three steps. First, we design a hierarchical clustering analysis (HCA) algorithm to divide the entire RAN into sub- RANs. Second, we implement a traffic load balancing algorithm to characterize the performance of the network partitioning. Third, we adapt the weights of networking features in the HCA algorithm to optimize the network partitioning. We validate the proposed solution through simulations designed based on real mobile network traffic data. The simulation results reveal the impacts of the RAN partitioning on the networking performance and the computational complexity of the networking mechanism.
22.Big Data Set Privacy Preserving through Sensitive Attribute-based Grouping
There is a growing trend towards attacks on database privacy due to great value of privacy information stored in big data set. Public’s privacy are under threats as adversaries are continuously cracking their popular targets such as bank accounts. We find a fact that existing models such as K-anonymity, group records based on quasi-identifiers, which harms the data utility a lot. Motivated by this, we propose a sensitive attribute-based privacy model.
Our model is the early work of grouping records based on sensitive attributes instead of quasi-identifiers which is popular in existing models. Random shuffle is used to maximize information entropy inside a group while the marginal distribution maintains the same before and after shuffling, therefore, our method maintains a better data utility than existing models. We have conducted extensive experiments which confirm that our model can achieve a satisfying privacy level without sacrificing data utility while guarantee a higher efficiency.
23.Big Data Driven Information Diffusion Analysis and Control in Online Social Networks
Thanks to recent advance in massive social data and increasingly mature big data mining technologies, information diffusion and its control strategies have attracted much attention, which play pivotal roles in public opinion control, virus marketing as well as other social applications. In this paper, relying on social big data, we focus on the analysis and control of information diffusion.
Specifically, we commence with analyzing the topological role of the social strengths, i.e., tie strength, partial strength, value strength, and their corresponding symmetric as well as asymmetric forms. Then, we define two critical points for the cascade information diffusion model, i.e., the information coverage critical point (CCP) and the information heat critical point (HCP). Furthermore, based on the two real-world datasets, the proposed two critical points are verified and analyzed. Our work may be beneficial in terms of analyzing and designing the information diffusion algorithms and relevant control strategies.
24.Big Data Analytics of Geosocial Media for Planning and Real-Time Decisions
Geosocial Network data can be served as an asset for the authorities to make real-time decisions and future planning by analyzing geosocial media posts. However, there are millions of Geosocial Network users who are producing overwhelming of data, called “Big Data” that is challenging to be analyzed and make real-time decisions. Therefore, in this paper, we proposed an efficient system for exploring Geosocial Networks while harvesting data as well as user’s location information.
A system architecture is proposed that processes an abundant amount of various social networks’ data to monitor Earth events, incidents, medical diseases, user trends, and views to make future real-time decisions and facilitate future planning. The proposed system consists of five layers, i.e., data collection, data processing, application, communication, and data storage. The system deploys Spark at the top of the Hadoop ecosystem in order to run real-time analyses.
Twitter and Flickr are analyzed using the proposed architecture in order to identify current events or disasters, such as earthquakes, fires, Ebola virus, and snow. The system is evaluated with respect to efficiency while considering system throughput. We proved that the system has higher throughput and is capable of analyzing massive Geosocial Network data at real-time.
25.An Approximate Search Framework for Big Data
In the age of big data, a traditional scanning search pattern is gradually becoming unfit for a satisfying user experience due to its lengthy computing process. In this paper, we propose a sampling-based approximate search framework called Hermes, to meet user’s query demand for both accurate and efficient results. A novel metric, (ε, δ)-approximation, is presented to uniformly measure accuracy and efficiency for a big data search service, which enables Hermes to work out a feasible searching job.
Based on this, we employ the bootstrapping technique to further speed up the search process. Moreover, an incremental sampling strategy is investigated to process homogeneous queries; in addition, the reuse theory of historical results is also studied for the scenario of appending data. Theoretical analyses and experiments on a real-world dataset demonstrate that Hermes is capable of producing approximate results meeting the preset query requirements with both high accuracy and efficiency.
26.A Reliable Task Assignment Strategy for Spatial Crowdsourcing in Big Data Environment
With the ubiquitous deployment of the mobile devices with increasingly better communication and computation capabilities, an emerging model called spatial crowdsourcing is proposed to solve the problem of unstructured big data by publishing location-based tasks to participating workers. However, massive spatial data generated by spatial crowdsourcing entails a critical challenge that the system has to guarantee quality control of crowdsourcing.
This paper first studies a practical problem of task assignment, namely reliability aware spatial crowdsourcing (RA-SC), which takes the constrained tasks and numerous dynamic workers into consideration. Specifically, the worker confidence is introduced to reflect the completion reliability of the assigned task. Our RA-SC problem is to perform task assignments such that the reliability under budget constraints is maximized.
Then, we reveal the typical property of the proposed problem, and design an effective strategy to achieve a high reliability of the task assignment. Besides the theoretical analysis, extensive experimental results also demonstrate that the proposed strategy is stable and effective for spatial crowdsourcing.
27.A Queuing Method for Adaptive Censoring in Big Data Processing
As more than 2.5 quintillion bytes of data are generated every day, the era of big data is undoubtedly upon us. Running analysis on extensive datasets is a challenge. Fortunately, a significant percentage of the data accrued can be omitted while maintaining a certain quality of statistical inference in many cases. Censoring provides us a natural option for data reduction. However, the data chosen by censoring occur nonuniformly, which may not relieve the computational resource requirement.
In this paper, we propose a dynamic, queuing method to smooth out the data processing without sacrificing the convergence performance of censoring. The proposed method entails simple, closed-form updates, and has no loss in terms of accuracy comparing to the original adaptive censoring method.Simulation results validate its effectiveness.
28.Achieving Efficient and Privacy-Preserving Cross-Domain Big Data Deduplication in Cloud
Secure data deduplication can significantly reduce the communication and storage overheads in cloud storage services, and has potential applications in our big data-driven society. Existing data deduplication schemes are generally designed to either resist brute-force attacks or ensure the efficiency and data availability, but not both conditions. We are also not aware of any existing scheme that achieves accountability, in the sense of reducing duplicate information disclosure (e.g., to determine whether plaintexts of two encrypted messages are identical).
In this paper, we investigate a three-tier cross-domain architecture, and propose an efficient and privacy-preserving big data deduplication in cloud storage (hereafter referred to as EPCDD). EPCDD achieves both privacy-preserving and data availability, and resists brute-force attacks. In addition, we take accountability into consideration to offer better privacy assurances than existing schemes. We then demonstrate that EPCDD outperforms existing competing schemes, in terms of computation, communication and storage overheads. In addition, the time complexity of duplicate search in EPCDD is logarithmic.
29.A Profile-Based Big Data Architecture for Agricultural Context
Bringing Big data technologies into agriculture presents a significant challenge; at the same time, this technology contributes effectively in many countries’ economic and social development. In this work, we will study environmental data provided by precision agriculture information technologies, which represents a crucial source of data in need of being wisely managed and analyzed with appropriate methods and tools in order to extract the meaningful information.
Our main purpose through this paper is to propose an effective Big data architecture based on profiling system which can assist (among others) producers, consulting companies, public bodies and research laboratories to make better decisions by providing them real time data processing, and a dynamic big data service composition method, to enhance and monitor the agricultural productivity. Thus, improve their traditional decision making process, and allow better management of the natural resources.
30.Review Based Service Recommendation for Big Data
Success of web 2.0 brings online information overload. An exponential growth of customers, services and online information has been observed in last decade. It yields big data investigation problem for service recommendation system. Traditional recommender systems often put up with scalability, lack of security and efficiency problems. Users preferences are almost ignored. So, the requirement of robust recommendation system is enhanced now a days.
In this paper, we present review based service recommendation to dynamically recommend services to the users. Keywords are extracted from passive users
reviews and a rating value is given to every new keyword observed in the dataset. Sentiment analysis is performed on these rating values and top-k services recommendation list is provided to users. To make the system more effective and robust hadoop framework is used.
31.Big Data Challenges in Smart Grid IoT (WAMS) Deployment
Internet of Things adoption across industries has proven to be beneficial in providing business value by transforming the way data is utilized in decision making and visualization. Power industry has for long struggled with traditional ways of operating and has suffered from issues like instability, blackouts,etc. The move towards smart grid has thus received lot of acceptance. This paper presents the Internet of Things deployment in grid, namely WAMS, and the challenges it present in terms of the Big Data it aggregates. Better insight into the problem is provided with the help of Indian Grid case studies.
32.A data mining framework to analyze road accident data
Road and traffic accidents are uncertain and unpredictable incidents and their analysis requires the knowledge of the factors affecting them. Road and traffic accidents are defined by a set of variables which are mostly of discrete nature. The major problem in the analysis of accident data is its heterogeneous nature [1]. Thus heterogeneity must be considered during analysis of the data otherwise, some relationship between the data may remain hidden. Although, researchers used segmentation of the data to reduce this heterogeneity using some measures such as expert knowledge, but there is no guarantee
that this will lead to an optimal segmentation which consists of homogeneous groups of road accidents [2]. Therefore, cluster analysis can assist the segmentation of road accidents.
33.A Time Efficient Approach for Detecting Errors in Big Sensor Data on Cloud
Big sensor data is prevalent in both industry and scientific research applications where the data is generated with high volume and velocity it is difficult to process using on-hand database management tools or traditional data processing applications. Cloud computing provides a promising platform to support the addressing of this challenge as it provides a flexible stack of massive computing, storage, and software services in a scalable manner at low cost. Some techniques have been developed in recent years for processing sensor data on cloud, such as sensor-cloud. However, these techniques do not provide efficient support on fast detection and locating of errors in big sensor data sets.
For fast data error detection in big sensor data sets, in this paper, we develop a novel data error detection approach which exploits the full computation potential of cloud platform and the network feature of WSN. Firstly, a set of sensor data error types are classified and defined. Based on that classification, the network feature of a clustered WSN is introduced and analyzed to support fast error detection and location. Specifically, in our proposed approach, the error detection is based on the scale-free network topology and most of detection operations can be conducted in limited temporal or spatial data blocks instead of a whole big data set.
Hence the detection and location process can be dramatically accelerated. Furthermore, the detection and location tasks can be distributed to cloud platform to fully exploit the computation power and massive storage. Through the experiment on our cloud computing platform of U-Cloud, it is demonstrated that our proposed approach can significantly reduce the time for error detection and location in big data sets generated by large scale sensor network systems with acceptable error detecting accuracy.
34.Big data, big knowledge: big data for personalised healthcare
The idea that the purely phenomenological knowledge that we can extract by analysing large amounts of data can be useful in healthcare seems to contradict the desire of VPH researchers to build detailed mechanistic models for individual patients. But in practice no model is ever entirely phenomenological or entirely mechanistic. We propose in this position paper that big data analytics can be successfully combined with VPH technologies to produce robust and effective in silico medicine solutions.
In order to do this, big data technologies must be further developed to cope with some specific requirements that emerge from this application. Such requirements are: working with sensitive data; analytics of complex and heterogeneous data spaces, including non-textual information; distributed data management under security and performance constraints; specialised analytics to integrate bioinformatics and systems biology information with clinical observations at tissue, organ and organisms scales; and specialised analytics to define the “physiological envelope” during the daily life of each patient. These domain-specific requirements suggest a need for targeted funding, in which big data technologies for in silico medicine becomes the research priority.
35.Deduplication on Encrypted Big Data in Cloud
Cloud computing offers a new way of service provision by re-arranging various resources over the Internet. The most important and popular cloud service is data storage. In order to preserve the privacy of data holders, data are often stored in cloud in an encrypted form. However, encrypted data introduce new challenges for cloud data deduplication, which becomes crucial for big data storage and processing in cloud. Traditional deduplication schemes cannot work on encrypted data. Existing solutions of encrypted data deduplication suffer from security weakness.
They cannot flexibly support data access control and revocation. Therefore, few of them can be readily deployed in practice. In this paper, we propose a scheme to deduplicate encrypted data stored in cloud based on ownership challenge and proxy re-encryption. It integrates cloud data deduplication with access control. We evaluate its performance based on extensive analysis and computer simulations. The results show the superior efficiency and effectiveness of the scheme for potential practical deployment, especially for big data deduplication in cloud storage.
36.Processing Geo-Dispersed Big Data in an Advanced MapReduce Framework
Big data takes many forms, including messages in social networks, data collected from various sensors, captured videos, and so on. Big data applications aim to collect and analyze large amounts of data, and efficiently extract valuable information from the data. A recent report shows that the amount of data on the Internet is about 500 billion GB. With the fast increase of mobile devices that can perform sensing and access the Internet, large amounts of data are generated daily.
In general, big data has three features: large volume, high velocity and large variety [1]. The International Data Corporation (IDC) predicted that the total amount of data generated in 2020 globally will be about 35 ZB. Facebook needs to process about 1.3 million TB of data each month. Many new data are generated at high velocity. For example, more than 2 million emails are sent over the Internet every second.
37.Recent Advances in Autonomic Provisioning of Big Data Applications on Clouds
CLOUD computing [1] assembles large networks of virtualized ICT services such as hardware resources (such as CPU, storage, and network), software resources (such as databases, application servers, and web servers) and applications.In industry these services are referred to as infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS). Mainstream ICT powerhouses such as Amazon, HP, and IBM are heavily investing in the provision and support of public cloud infrastructure.
Cloud computing is rapidly becoming a popular infrastructure of choice among all types of organisations. Despite some initial security concerns and technical issues, an increasing number of organisations have moved their applications and services in to “The Cloud”. These applications range from generic word processing software to online healthcare. The cloud system taps into the processing power of virtualized computers on the back end, thus significantly speeding up the application for the user, which just pays for the used services.
38.Privacy Preserving Data Analysis in Mental Health Research
The digitalization of mental health records and psychotherapy notes has made individual mental health data more readily accessible to a wide range of users including patients, psychiatrists, researchers, statisticians, and data scientists. However, increased accessibility of highly sensitive mental records threatens the privacy and confidentiality of psychiatric patients. The objective of this study is to examine privacy concerns in mental health research and develop a privacy preserving data analysis approach to address these concerns.
In this paper, we demonstrate the key inadequacies of the existing privacy protection approaches applicable to use of mental health records and psychotherapy notes in records based research. We then develop a privacy-preserving data analysis approach that enables researchers to protect the privacy of people with mental illness once granted access to mental health records. Furthermore, we choose a demonstration project to show the use of the proposed approach. This paper concludes by suggesting practical implications for mental health researchers and future research in the field of privacy-preserving data analytics.
39.BFC: High-Performance Distributed Big-File Cloud Storage Based On Key-Value Store
Nowadays, cloud-based storage services are rapidly growing and becoming an emerging trend in data storage field. There are many problems when designing an efficient storage engine for cloud-based systems with some requirements such as big-file processing, lightweight meta-data, low latency, parallel I/O, deduplication, distributed, high scalability. Key-value stores played an important role and showed many advantages when solving those problems. This paper presents about Big File Cloud (BFC) with its algorithms and architecture to handle most of problems in a big-file cloud storage system based on key value store.
It is done by proposing low-complicated, fixed-size meta-data design, which supports fast and highly-concurrent, distributed file I/O, several algorithms for resumable upload, download and simple data deduplication method for static data. This research applied the advantages of ZDB - an in-house key value store which was optimized with auto-increment integer keys for solving big-file storage problems efficiently. The results can be used for building scalable distributed data cloud storage that support big-file with size up to several terabytes
40.Performance Analysis of Scheduling Algorithms for Dynamic Workflow Applications
In recent years, Big Data has changed how we do computing. Even though we have large scale infrastructure such as Cloud computing and several platforms such as Hadoop available to process the workloads, with Big Data there is a high level of uncertainty that has been introduced in how an application processes the data. Data in general comes in different formats, at different speed and at different volume.
Processing consists of not just one application but several applications combined to form a workflow to achieve a certain goal. With data variation and at different speed, applications execution and resource needs will also vary at runtime. These are called dynamic workflows. One can say that we can just throw more and more resources during runtime.
However this is not an effective way as it can lead to, in the best case, resource wastage or monetary loss and in the worst case, delivery of outcomes much later than when it is required. Thus, scheduling algorithms play an important role in efficient execution of dynamic workflow applications. In this paper, we evaluate several most commonly used workflow scheduling algorithms to understand which algorithm will be the best for the efficient execution of dynamic workflows.
41.PaWI: Parallel Weighted Itemset Mining by means of MapReduce
Frequent itemset mining is an exploratory data mining technique that has fruitfully been exploited to extract recurrent co-occurrences between data items. Since in many application contexts items are enriched with weights denoting their relative importance in the analyzed data, pushing item weights into the itemset mining process, i.e., mining weighted itemsets rather than traditional itemsets, is an appealing research direction. Although many efficient in-memory weighted itemset mining algorithms are available in literature, there is a lack of parallel and distributed solutions which are able to scale towards Big Weighted Data.
This paper presents a scalable frequent weighted itemset mining algorithm based on the MapReduce paradigm. To demonstrate its actionability and scalability, the proposed algorithm was tested on a real Big dataset collecting approximately 34 millions of reviews of Amazon items. Weights indicate the ratings given by users to the purchased items. The mined itemsets represent combinations of items that were frequently bought together with an overall rating above average.
42.Building a Big Data Analytics Service Framework for Mobile Advertising and Marketing
The unprecedented growth in mobile device adoption and the rapid advancement of mobile technologies & wireless networks have created new opportunities in mobile marketing and adverting. The opportunities for Mobile Marketers and Advertisers include real-time customer engagement, improve customer experience, build brand loyalty, increase revenues, and drive customer satisfaction. The challenges, however, for the Marketers and Advertisers include how to analyze troves of data that mobile devices emit and how to derive customer engagement insights from the mobile data.
This research paper addresses the challenge by developing Big Data Mobile Marketing analytics and advertising recommendation framework. The proposed framework supports both offline and online advertising operations in which the selected analytics techniques are used to provide advertising recommendations based on collected Big Data on mobile user's profiles, access behaviors, and mobility patterns. The paper presents prototyping solution design as well as its application and certain experimental results.
43.Secure Sensitive Data Sharing on a Big Data Platform
Users store vast amounts of sensitive data on a big data platform. Sharing sensitive data will help enterprises reduce the cost of providing users with personalized services and provide value-added data services. However, secure data sharing is problematic. This paper proposes a framework for secure sensitive data sharing on a big data platform, including secure data delivery, storage, usage, and destruction on a semi-trusted big data sharing platform.
We present a proxy re-encryption algorithm based on heterogeneous ciphertext transformation and a user process protection method based on a virtual machine monitor, which provides support for the realization of system functions. The framework protects the security of users’ sensitive data effectively and shares these data safely. At the same time, data owners retain complete control of their own data in a sound environment for modern Internet information security.
44.Load Balancing for Privacy-Preserving Access to Big Data in Cloud
In the era of big data, many users and companies start to move their data to cloud storage to simplify data management and reduce data maintenance cost. However, security and privacy issues become major concerns because third-party cloud service providers are not always trusty. Although data contents can be protected by encryption, the access patterns that contain important information are still exposed to clouds or malicious attackers.
In this paper, we apply the ORAM algorithm to enable privacy-preserving access to big data that are deployed in distributed file systems built upon hundreds or thousands of servers in a single or multiple geo-distributed cloud sites. Since the ORAM algorithm would lead to serious access load unbalance among storage servers, we study a data placement problem to achieve a load balanced storage system with improved availability and responsiveness.
Due to the NP-hardness of this problem, we propose a low-complexity algorithm that can deal with large-scale problem size with respect to big data. Extensive simulations are conducted to show that our proposed algorithm finds results close to the optimal solution, and significantly outperforms a random data placement algorithm.
45.Enabling Efficient Access Control with Dynamic Policy Updating for Big Data in the Cloud
Due to the high volume and velocity of big data, it is an effective option to store big data in the cloud, because the cloud has capabilities of storing big data and processing high volume of user access requests. Attribute-Based Encryption (ABE) is a promising technique to ensure the end-to-end security of big data in the cloud. However, the policy updating has always been a challenging issue when ABE is used to construct access control schemes. A trivial implementation is to let data owners retrieve the data and re-encrypt it under the new access policy, and then send it back to the cloud.
This method incurs a high communication overhead and heavy computation burden on data owners. In this paper, we propose a novel scheme that enabling efficient access control with dynamic policy updating for big data in the cloud. We focus on developing an outsourced policy updating method for ABE systems. Our method can avoid the transmission of encrypted data and minimize the computation work of data owners, by making use of the previously encrypted data with old access policies. Moreover, we also design policy updating algorithms for different types of access policies. The analysis show that our scheme is correct, complete, secure and efficient.
46.MRPrePost-A parallel algorithm adapted for mining big data
With the explosive growth in data, using data mining techniques to mine association rules, and then to find valuable information hidden in big data has become increasingly important. Various existing data mining techniques often through mining frequent itemsets to derive association rules and access to relevant knowledge, but with the rapid arrival of the era of big data, Traditional data mining algorithms have been unable to meet large data's analysis needs.
In view of this, this paper proposes an adaptation to the big data mining parallel algorithms-MRPrePost. MRPrePost is a parallel algorithm based on Hadoop platform, which improves PrePost by way of adding a prefix pattern, and on this basis into the parallel design ideas, making MR PrePost algorithm can adapt to mining large data's association rules. Experiments show that MRPrePost algorithm is more superior than PrePost and PFP in terms of performance, and the stability and scalability of algorithms are better.
47.Privacy Preserving Data Analytics for Smart Homes
A framework for maintaining security & preserving privacy for analysis of sensor data from smart homes, without compromising on data utility is presented. Storing the personally identifiable data as hashed values withholds identifiable information from any computing nodes. However the very nature of smart home data analytics is establishing preventive care. Data processing results should be identifiable to certain users responsible for direct care.
Through a separate encrypted identifier dictionary with hashed and actual values of all unique sets of identifiers, we suggest re-identification of any data processing results.However the level of re-identification needs to be controlled, depending on the type of user accessing the results. Generalization and suppression on identifiers from the identifier dictionary before re-introduction could achieve different levels of privacy preservation. In this paper we propose an approach to achieve data security & privacy through out the complete data lifecycle:data generation/collection, transfer, storage, processing and sharing.
48.Authorized Public Auditing of Dynamic Big Data Storage on Cloud with Efficient Verifiable Fine-grained Updates
Cloud computing opens a new era in IT as it can provide various elastic and scalable IT services in a pay-as-you-go fashion, where its users can reduce the huge capital investments in their own IT infrastructure. In this philosophy, users of cloud storage services no longer physically maintain direct control over their data, which makes data security one of the major concerns of using cloud. Existing research work already allows data integrity to be verified without possession of the actual data file.
When the verification is done by a trusted third party, this verification process is also called data auditing, and this third party is called an auditor. However, such schemes in existence suffer from several common drawbacks. First, a necessary authorization/authentication process is missing between the auditor and cloud service provider, i.e., anyone can challenge the cloud service provider for a proof of integrity of certain file, which potentially puts the quality of the so-called ‘auditing-as-a service’ at risk; Second, although some of the recent work based on BLS signature can already support fully dynamic data updates over fixed-size data blocks, they only support updates with fixed-sized blocks as basic unit, which we call coarse grained updates.
As a result, every small update will cause re-computation and updating of the authenticator for an entire file block, which in turn causes higher storage and communication overheads. In this paper, we provide a formal analysis for possible types of fine-grained data updates and propose a scheme that can fully support authorized auditing and fine-grained update requests. Based on our scheme, we also propose an enhancement that can dramatically reduce communication overheads for verifying small updates. Theoretical analysis and experimental results demonstrate that our scheme can offer not only enhanced security and flexibility, but also significantly lower overhead for big data applications with a large number of frequent small updates, such as applications in social media and business transactions.
49.KASR: A Keyword-Aware Service Recommendation Method on MapReduce for Big Data
Applications Service recommender systems have been shown as valuable tools for providing appropriate recommendations to users. In the last decade, the amount of customers, services and online information has grown rapidly, yielding the big data analysis problem for service recommender systems. Consequently, traditional service recommender systems often suffer from scalability and inefficien-cy problems when processing or analysing such large-scale data. Moreover, most of existing service recommender systems present the same ratings and rankings of services to different users without considering diverse users' preferences, and therefore fails to meet users' personalized requirements.
In this paper, we propose a Keyword-Aware Service Recommendation method, named KASR, to address the above challenges. It aims at presenting a personalized service recommendation list and recommending the most appropriate services to the users effectively. Specifically, keywords are used to indicate users' preferences, and a user-based Collaborative Filtering algorithm is adopted to generate appropriate recommendations. To improve its scalability and efficiency in big data environ-ment, KASR is implemented on Hadoop, a widely-adopted distributed computing platform using the MapReduce parallel processing paradigm. Finally, extensive experiments are conducted on real-world data sets, and results demonstrate that KASR significantly im-proves the accuracy and scalability of service recommender systems over existing approaches.
50.Cost Minimization for Big Data Processing in Geo-Distributed Data Centers
The explosive growth of demands on big data processing imposes a heavy burden on computation, storage, and communication in data centers, which hence incurs considerable operational expenditure to data center providers. Therefore, cost minimization has become an emergent issue for the upcoming big data era.
Different from conventional cloud services, one of the main features of big data services is the tight coupling between data and computation as computation tasks can be conducted only when the corresponding data is available. As a result, three factors, i.e., task assignment, data placement and data movement, deeply influence the operational expenditure of data centers.
In this paper, we are motivated to study the cost minimization problem via a joint optimization of these three factors for big data services in geo-distributed data centers. To describe the task completion time with the consideration of both data transmission and computation, we propose a two-dimensional Markov chain and derive the average task completion time in closed-form. Furthermore, we model the problem as a mixed-integer non-linear programming (MINLP) and propose an efficient solution to linearize it. The high efficiency of our proposal is validated by extensive simulation based studies.
51.Dache: A Data Aware Caching for Big-Data Applications Using the MapReduce Framework
The buzz-word big-data refers to the large-scale distributed data processing applications that operate on exceptionally large amounts of data. Google’s MapReduce and Apache's Hadoop, its open-source implementation, are the de facto software systems for big-data applications. An observation of the MapReduce framework is that the framework generates a large amount of intermediate data. Such abundant information is thrown away after the tasks finish, because MapReduce is unable to utilize them.
In this paper, we propose Dache, a data-aware cache framework for big-data applications. In Dache, tasks submit their intermediate results to the cache manager. A task queries the cache manager before executing the actual computing work. A novel cache description scheme and a cache request and reply protocol are designed. We implement Dache by extending Hadoop. Testbed experiment results demonstrate that Dache significantly improves the completion time of MapReduce jobs.
52.ClubCF: A Clustering-based Collaborative Filtering Approach for Big Data Application
Spurred by service computing and cloud computing, an increasing number of services are emerging on the Internet. As a result, service-relevant data become too big to be effectively processed by traditional approaches. In view of this challenge, a Clustering-based Collaborative Filtering approach (ClubCF) is proposed in this paper, which aims at recruiting similar services in the same clusters to recommend services collaboratively. Technically, this approach is enacted around two stages.
In the first stage, the available services are divided into small-scale clusters, in logic, for further processing. At the second stage, a collaborative filtering algorithm is imposed on one of the clusters. Since the number of the services in a cluster is much less than the total number of the services available on the web, it is expected to reduce the online execution time of collaborative filtering. At last, several experiments are conducted to verify the availability of the approach, on a real dataset of 6,225 mashup services collected from ProgrammableWeb.
Big data is a term for data sets that are so large or complex that traditional data processing applications are inadequate. Challenges include analysis, capture, data duration, search, sharing, storage, transfer, visualization, querying and information privacy. The term often refers simply to the use of predictive analytics and Analysis of data sets can find new correlations to "spot business trends, prevent diseases, and combat crime and so on. Projects on Big Data are growing rapidly because they are increasingly gathered by cheap and numerous information-sensing mobile devices, aerial (remote sensing), software logs, cameras, microphones, radio-frequency identification (RFID) readers and wireless sensor networks.
Characteristics of projects on Big Data
Big data can be described by the following characteristics
-
1)Veracity The quality of Data captured can vary greatly, affecting accurate analysis.
-
2)Volume The quantity of generated and Data stored. The size of the data determines the value and potential insight and whether it can actually be considered big data or not.
-
3)Velocity In this context, the speed at which the data is generated and processed to meet the demands and challenges that lie in the path of growth and development.
-
4)Variability Inconsistency of the data set can hamper processes to handle and manage it.
-
5)Variety Type and nature of the data. This helps people who analyze it to effectively use the resulting insight.
Data must be processed with advanced tools (analytics and algorithms) to reveal meaningful information. For example, to manage a factory one must consider both visible and invisible issues with various components. Information generation algorithms must detect and address invisible issues such as machine degradation, component wear, etc. on the factory floor so these things we can study in Projects on Big Data.
Big Data for Engineering Students

Engineering students should choose big data for his final year project, because it Big-Data is the future of modern data science. We have best 2022-2023 for engineering students ideas, which is going to be extremely useful in day to day life. At CITL you will get expert training for any kind of projects based on Big Data. Engineering students can do their Big-Data projects on these area
-
Real time data recovery, getting missing values
-
Social Marketing Footprint discovery and analysis for Marketing
-
Smart City Maintenance, and Data Management system 2018
-
Auto spelling and grammar detection and correction
-
Human Activity Recognition, Public Transport, Machine Learning
-
Cloud computing object storage and integration system
-
DNA Database storage and analysis
-
Real Time query answering system form Big Data Source
Attend your big data final year projects at our institute in Bangalore or take online direct training classes from anywhere in India or world. Get top quality and trending IEEE from here and do it by yourself. We are continuously adding more big data final year project ideas, so you could find new opportunities in Big Data Science. Take reference or would like to start your training from our or yours idea on .
Find latest 2023 topic ideas for M.Tech students, and for B.Tech,BE final year students. Let us know your feedback and new ideas on .
Leave Your Comment Here