
Latest 2023 IEEE projects on, and Cyber Security. has emerged in recent few years and has huge opportunity in the future. We help engineering and computer science Students to make their best project for final year at very economic price. We have quick mini-projects as well as you can get help in your own project idea. We follow every standard of IEEE final year project guideline and deliver successful data and projects.
Generally, is the process of analyzing data from different perspectives and summarizing it into useful information - information that can be used to increase revenue, cuts costs, or both. software is one of a number of analytical tools for analyzing data allows users to analyze data from many different dimensions or angles, categorize it, and summarize the relationships identified. Technically, is the process of finding correlations or patterns among dozens of fields in large r
1.A Public Opinion Keyword Vector for Social Sentiment Analysis Research
In the Internet era, online platforms are the most convenient means for people to share and retrieve knowledge. Social media enables users to easily post their opinions and perspectives regarding certain issues. Although this convenience lets the internet become a treasury of information, the overload also prevents user from understanding the entirety of various events. This research aims at using text mining techniques to explore public opinion contained in social media by analyzing the reader’s emotion towards pieces of short text.
We propose Public Opinion Keyword Embedding (POKE) for the presentation of short texts from social media, and a vector space classifier for the categorization of opinions. The experimental results demonstrate that our method can effectively represent the semantics of short text public opinion. In addition, we combine a visualized analysis method for keywords that can provide a deeper understanding of opinions expressed on social media topics.
Looking for Project Development Guide ? , Join Our Next Batch for End to end Advise from Experts

2.A Framework for Sentiment Analysis with Opinion Mining of Hotel Reviews
The rapid increase in mountains of unstructured textual data accompanied by proliferation of tools to analyse them has opened up great opportunities and challenges for text mining research. The automatic labelling of text data is hard because people often express opinions in complex ways that are sometimes difficult to comprehend. The labelling process involves huge amount of efforts and mislabelled datasets usually lead to incorrect decisions.
In this paper, we design a framework for sentiment analysis with opinion mining for the case of hotel customer feedback.Most available datasets of hotel reviews are not labelled which presents a lot of works for researchers as far as text data pre-processing task is concerned. Moreover, sentiment datasets are often highly domain sensitive and hard to create because sentiments are feelings such as emotions, attitudes and opinions that are commonly rife with idioms, onomatopoeias, homophones, phonemes, alliterations and acronyms.
The proposed framework is termed sentiment polarity that automatically prepares a sentiment dataset for training and testing to extract unbiased opinions of hotel services from reviews. A comparati ve analysis was established with Naïve Bayes multinomial, sequential minimal optimization, compliment Naïve Bayes and Composite hypercubes on iterated random projections to discover a suitable machine learning algorithm for the classification component of the framework.
3.Get To The Point: Summarization with Pointer-Generator Networks
Neural sequence-to-sequence models have provided a viable new approach for abstractive text summarization (meaning they are not restricted to simply selecting and rearranging passages from the original text). However, these models have two shortcomings: they are liable to reproduce factual details inaccurately, and they tend to repeat themselves. In this work we propose a novel architecture that augments the standard sequence-to-sequence attentional model in two orthogonal ways.
First, we use a hybrid pointer-generator network that can copy words from the source text via pointing, which aids accurate reproduction of information, while retaining the ability to produce novel words through the generator. Second, we use coverage to keep track of what has been summarized, which discourages repetition. We apply our model to the CNN / Daily Mail summarization task, outperforming the current abstractive state-of-the-art by at least 2 ROUGE points.
System Architecture
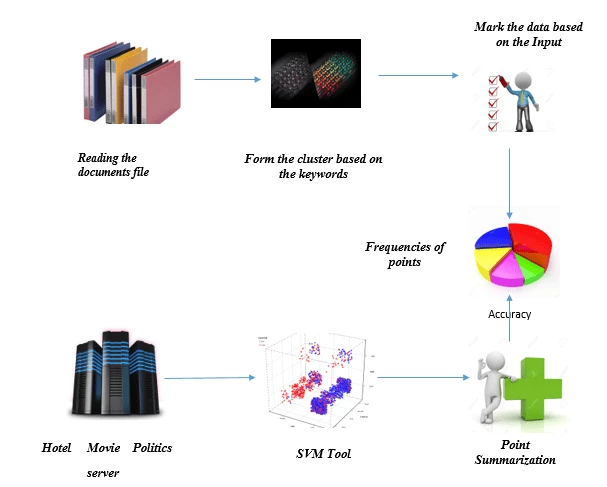
Project Overview Marking the keywords without knowing the dictionary is a big issue and that too with relative data. Here the data will be having offline dictionary for proper marking with summarization. So here the data marking is done with respect to offline dictionary and once the same data sent to server where the machine learning happening and point summarization updates and will be changed according to the future dictionary.
System Requirement
Hardware Requirement
Processor - Dual Core
Speed - 1.1 G Hz
RAM - 512 MB (min)
Hard - 20 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Software Requirement
Operating System : Windows xp,7,8
Front End : Java 7
Technology : Swings,Core java
IDE : Netbeans.
Below code is for highlighting the content in the document.
Highlighter highlighter = mainTextContent.getHighlighter();
HighlightPainter painter = new DefaultHighlighter.DefaultHighlightPainter(Color.YELLOW);
mainTextContent.setHighlighter(highlighter);
4.Monitoring vehicle speed using GPS and categorizing driver using data mining approach
The GPS signals received from smart phone device will be used to monitor the person when he is driving .The coordinates received from the GPS is stored in the Cloud. This data is further used to monitor the speed at which the person is driving. Information is maintained about each person and if the person crosses a threshold speed he is categorized as a driver. This way motor insurance companies have the potential to provide customized solutions to their clients.
System Architecture
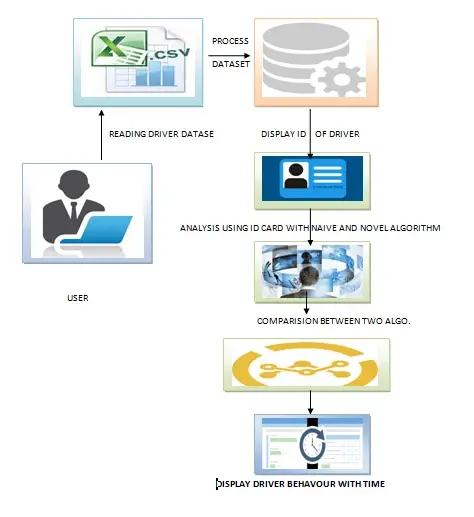
Project Overview Fetch the data of past data of the drivers past history and by applying the naive and novel approaches the driver's rashness prediction can happen in peak and non peak hours. Both algorithms compares for the accuracy of the prediction.
System Requirement
Hardware Requirement
Processor - Dual Core
Speed - 1.1 G Hz
RAM - 512 MB (min)
Hard - 20 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Software Requirement
Operating System : Windows xp,7,8
Front End : Java 7
Technology : Swings, Core java.
IDE : Netbeans.
Below code is for comparison of driver prediction
long cluster Process Time = 0;
long naive Process Time = 0;
int clusterComparativeFreq = 0;
int naiveComparativeFreq = 0;

5.Segmenting customers with Data Mining Techniques.
Retail marketers are constantly looking for ways to improve the effectiveness of their campaigns. One way to do this is to target customers with the particular offers most likely to attract them back to the store and to spend more time and money on their next visit. Demographic market segmentation is an approach to segmenting markets. A company divides the larger market into groups based on several defined criteria.
Age, gender, marital status, occupation, education and income are among the commonly considered demographics segmentation criteria. A sample case study has been done in order to explain the theory of segmentation applied on a Turkish supermarket chain. The purpose of this case study is to determine dependency on products and shopping habits. Furthermore forecast sales determine the promotions of products and customer profiles. Association rule mining was used as a method for identifying customers buying patterns and as a result customer profiles were determined.
Besides association rules, interesting results were found about customer profiles, such as “What items do female customers buy?” or “What do consumers(married and 35-45 aged) prefer mostly?”. For instance, female customers purchase feta cheese with a percentage of 60% whereas male customers purchase tomato with a percentage of 46%. Regarding to customers age, 65 and older customers purchase tea with a percentage of 58%, and customers aged between 18- 25 preferred pasta with a percentage of 57%
System Architecture
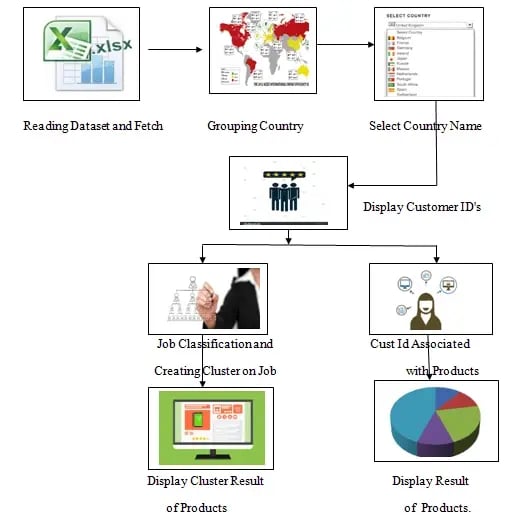 Project Overview
Project Overview
Reading the customers information with id and grouping with respect to countries and association with products and shows the accuracy of the association of customer association with products.
System Requirement
Hardware Requirement
Processor - Dual Core
Speed - 1.1 G Hz
RAM - 512 MB (min)
Hard - 20 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Software Requirement
Operating System : Windows xp,7,8
Front End : Java 7
Technology : Swings, Core java.
IDE : Netbeans.
The below code is to find the start time of the customers
long startTIme = System.currentTimeMillis();
ArrayList customerId = new ArrayList();
customerId.clear();
customerId = (ArrayList)at7.clone();
Set set = new HashSet(customerId);
customerId.clear();
customerId.addAll(set);

6.Incremental Semi-Supervised Clustering Ensemble for High Dimensional Data Clustering
Traditional cluster ensemble approaches have three limitations:
-
They do not make use of prior knowledge of the datasets given by experts.
-
Most of the conventional cluster ensemble methods cannot obtain satisfactory results when handling high dimensional data.
-
All the ensemble members are considered, even the ones without positive contributions.
In order to address the limitations of conventional cluster ensemble approaches, we first propose an -supervised clustering ensemble framework (ISSCE) which makes use of the advantage of the random subspace technique, the constraint propagation approach, the proposed incremental ensemble member selection process, and the normalized cut algorithm to perform high dimensional data clustering. The random subspace technique is effective for handling high dimensional data, while the constraint propagation approach is useful for incorporating prior knowledge. The incremental ensemble member selection process is newly designed to judiciously
remove redundant ensemble members based on a newly proposed local cost function and a global cost function, and the normalized cut algorithm is adopted to serve as the consensus function for providing more stable, robust, and accurate results. Then, a measure is proposed to quantify the similarity between two sets of attributes, and is used for computing the local cost function in ISSCE. Next, we analyze the time complexity of ISSCE theoretically. Finally, a set of nonparametric tests are adopted to compare multiple semi supervised clustering ensemble approaches over different datasets. The experiments on 18 real-world datasets, which include six UCI datasets and 12 cancer gene expression profiles, confirm that ISSCE works well on datasets
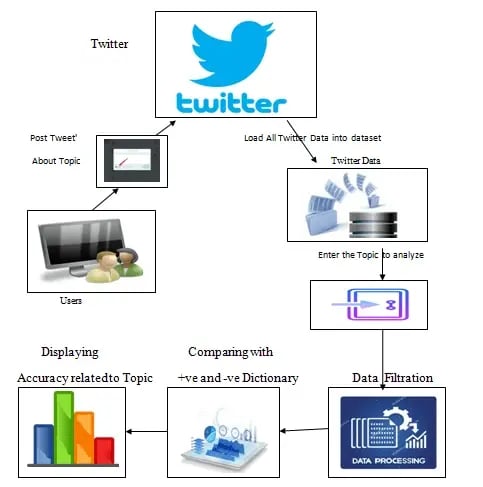
Project Overview After acquiring the twitter data and by taking the dictionaries(+ve and -ve) analysis will happen to prediction and +ve and -ve frequency for the recommendations.
System Configuration
Hardware Requirement
Processor - Dual Core
Speed - 1.1 G Hz
RAM - 512 MB (min)
Hard - 20 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Software Requirement
Operating System : Windows xp,7,8
Front End : Java 7
Technology : swings, core java
IDE : Netbeans
Below code shows how to load the tweets
FileInputStream fibs = new FileInputStream("text\\keywordP.txt");
byte bb1[] = new byte[fisP.available()];
fisP.read(bb1);
fisP.close();
String all String = new String(bb1);
7.Cricket data Analysis & Prediction
Data analysis is nothing new. Even before computers were used, information gained in the course of business or other activities was reviewed with the aim of making those processes more efficient and more profitable. These were, of course, comparatively small-scale undertakings given the limitations posed by resources and manpower; analysis had to be manual and was slow by modern standards, but it was still worthwhile.
Predictive analytics in sport is not new, but it’s a novel move in cricket. As it has been implemented in many other sports majorly in NBA basketball games, baseball and American football. So introducing it into the field of cricket is a new challenge which would definitely prove to be as successful and efficient as it has been in other fields. Taking the example of 2015 ICC Cricket World Cup, which was the most digitally advanced tournament in the history of cricket as the predictions that were made proved to be right. This served to be a motivation for this project.
System Architecture
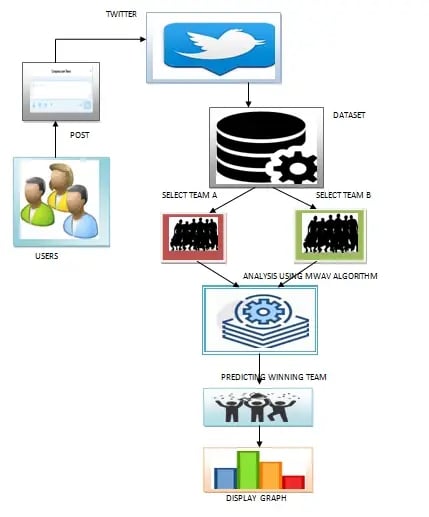
Project Overview
Initially we fetch the 2 opponent teams and based on their past career and by applying mean weighted vector, players will be recommended to play as batsmen and bowlers in both teams
System Requirement
Hardware Requirement
Processor - Dual Core
Speed - 1.1 G Hz
RAM - 512 MB (min)
Hard - 20 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Software Requirement
Operating System : Windows xp,7,8
Front End : Java 7
Technology : Html,JSp.
IDE : Netbeans.
Below code shows how to fetch the names of the different player from team.
try{
String names[] = request.getParameterValues("tplayer");
allSelected Names.clear();
for(int i=0;i<names.length;i++){ <br=""> allSelected Names.add(names[i]);
}</names.length;i++){>
8.Clustering Data Streams Based on Shared Density Between Micro-Clusters
As more and more applications produce streaming data, clustering data streams has become an important technique for data and knowledge engineering. A typical approach is to summarize the data stream in real-time with an online process into a large number of so called micro-. Micro- represent local density estimates by aggregating the information of many data points in a defined area. On demand, a (modified) conventional clustering algorithm is used in a second offline step to recluster the micro- into larger final .
For reclustering, the centers of the micro- are used as pseudo points with the density estimates used as their weights. However, information about density in the area between micro- is not preserved in the online process and reclustering is based on possibly inaccurate assumptions about the distribution of data within and between micro- (e.g., uniform or Gaussian). This paper describes DBSTREAM, the first micro-cluster-based online clustering component that explicitly captures the density between micro- via a shared density graph.
The density information in this graph is then exploited for re clustering based on actual density between adjacent micro-. We discuss the space and time complexity of maintaining the shared density graph. Experiments on a wide range of synthetic and real data sets highlight that using shared density improves clustering quality over other popular data stream clustering methods which require the creation of a larger number of smaller micro- to achieve comparable results.
Project Overview: Fetch medical (thyroid) data and cluster the data with respect the disease and later it recommends the associated doctors and prediction of best suitable doctor of the selected disease. Processing is happening over 5000 records.
System Requirement
Hardware Requirement
Processor - Dual Core
Speed - 1.1 G Hz
RAM - 512 MB (min)
Hard - 20 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Software Requirement
Operating System : Windows xp,7,8
Front End : Java 7
Technology : Swings, Core java.
IDE : Netbeans.
Sample Code
String disName = Disease.getSelectedItem ().toString();
ArrayList indexes= new ArrayList();
indexes.clear();
for(int i=0;i<drsname.size();i++) <br=""> {
if( decease.get(i).toString().equals(disName))
{
mainClusterIndexes.add(i);
indexes.add(i);
}
The above code show how to select the different disease names.
9.Track Summary Report for the Data Exploration in the Web 3.0 Age (DEW) Track
Since the introduction of process model for knowledge discovery [1], the importance of data mining methods is dramatically increased making this research area relevant and challenging to extract actionable knowledge from raw data. Data mining techniques discover useful information by analyzing data from multiple perspectives to deal with problems linked to information retrieval in different application domains.
This process can be endowed with external data that may lead to additional insights in a way that the user can benefit from it. For example, when dealing with politic data, an analyst presumably knows the name of the prime minister of worlds states. So, she could add a variable “prime-minister” to datasets under exploration in order to extract pertinent and useful information.
That example glimpses the enormous benefits that result from integrating raw data with the large amount of information related to new research domains such as big data, internet of things, cloud computing etc. It is well know that this information is available on the Web according to multiple modalities, multiple resources and multiple formats.
11.Privacy-Preserving Multiple Linear Regression of Vertically Partitioned Real Medical Datasets
This paper studies the feasibility of privacy preserving data mining in epidemiological study. As for the data mining algorithm, we focus to a linear multiple regression that can be used to identify the most significant factors among many possible variables, such as the history of many diseases. We try to identify the linear model to estimate a length of hospital stay from distributed dataset related to the patient and the disease information. In this paper, we have done experiment using the real medical dataset related to stroke and attempt to apply multiple regression with six predictors of age, sex, the medical scales, e.g., Japan Coma Scale, and the modified Rankin Scale.
Our contributions of this paper include (1) to propose a practical privacy-preserving protocols for linear multiple regression with vertically partitioned datasets, and (2) to show the feasibility of the proposed system using the real medical dataset distributed into two parties, the hospital who knows the technical details of diseases during the patients are in the hospital, and the local government who knows the residence even after the patients left hospital. (3) to show the accuracy and the performance of the PPDM system which allows us to estimate the expected processing time with arbitrary number of predictors.
12.Authenticated Outlier Mining for Outsourced Databases
The Data-Mining-as-a-Service (DMaS) paradigm is becoming the focus of research, as it allows the data owner (client) who lacks expertise and/or computational resources to outsource their data and mining needs to a third-party service provider (server). Outsourcing, however, raises some issues about result integrity: how could the client verify the mining results returned by the server are both sound and complete? In this paper, we focus on outlier mining, an important mining task.
Previous verification techniques use an authenticated data structure (ADS) for correctness authentication, which may incur much space and communication cost. In this paper, we propose a novel solution that returns a probabilistic result integrity guarantee with much cheaper verification cost. The key idea is to insert a set of artificial records (ARs) into the dataset, from which it constructs a set of artificial outliers (AOs) and artificial non-outliers (ANOs).
The AOs and ANOs are used by the client to detect any incomplete and/or incorrect mining results with a probabilistic guarantee. The main challenge that we address is how to construct ARs so that they do not change the (non-)out lierness of original records, while guaranteeing that the client can identify ANOs and AOs without executing mining. Furthermore, we build a strategic game and show that a Nash equilibrium exists only when the server returns correct outliers. Our implementation and experiments demonstrate that our verification solution is efficient and lightweight.
13.An Improved Vertical Algorithm for Frequent Itemset Mining from Uncertain Database
For the reason that the algorithm PFIM needs to scan database repeatedly,to produce a great deal of redundant candidate itemset,and to compute more time-complexity of frequent probability, an improved algorithm UPro-Eclat which is based on PFIM and Eclat is proposed.
It uses a vertical mining method which is extension-based,adds probabilistic information in Tid ,builds recursively the subset of search tree,and mines probabilistic frequent pattern by depth-first traversal. The algorithm UPro-Eclat can swiftly find probabilistic frequent itemset rather than compute their probability in each possible world.
14.A Survey on Political Event Analysis in Twitter.
This short survey paper attempts to provide an overview of the most recent research works on the popular politics domain within the framework of the Twitter social network. Given both the political turmoil that arouse at the end of 2016 and early 2017, and the increasing popularity of social networks in general, and Twitter, in particular, we feel that this topic forms an attractive candidate for fellow data mining researchers that came into sight over the last few months.
Herein, we start by presenting a brief overview of our motivation and continue with basic information on the Twitter platform, which constitutes two clearly identifiable components, namely as an online news source and as one of the most popular social networking sites. Focus is then given to research works dealing with sentiment analysis in political topics and opinion polls, whereas we continue by reviewing the Twittersphere from the computational social science point of view, by including behavior analysis, social interaction and social influence identification methods and by discerning and discriminating its useful types within the social network, thus envisioning possible further utilization scenarios for the collected information. A short discussion on the identified conclusions and a couple of future research directions concludes the survey.
15.A Non-Parametric Algorithm for Discovering Triggering Patterns of Spatio-Temporal Event Types
Temporal or spatio-temporal sequential pattern discovery is a well-recognized important problem in many domains like seismology, criminology and finance. The majority of the current approaches are based on candidate generation which necessitates parameter tuning namely,definition of a neighborhood, an interest measure and a threshold value to evaluate candidates. However, their performance is limited as the success of these methods relies heavily on parameter settings.
In this paper, we propose an algorithm which uses a nonparametric stochastic de-clustering procedure and a multivariate Hawkes model to define triggering relations within and among the event types and employs the estimated model to extract significant triggering patterns of event types. We tested the proposed method with real and synthetic data sets exhibiting different characteristics. The method gives good results that are comparable with the methods based on candidate generation in the literature.
16.A Cypher Query based NoSQL Data Mining on Protein Datasets using Neo4j Graph Database
Graph data analysis is one of the upcoming methodologies in various niches of computer science. Traditionally for storing, retrieving and experimenting test data, researchers start with mysql database which is more approachable and easier to build their test experimentation platform. These test bed mysql databases will store data in the form of rows and columns, over which various SQL queries are performed. At times when the structure and size of dataset changed, these traditional mysql databases become inefficient in storing and retrieving of data.
When the structure of dataset changes from row-column to graph representation, mysql database based querying and analysis become inefficient. The internal representation of data is changed to key-value pairs, more often the data in an unstructured format, which prompted the researchers to think about other databases which can achieve faster retrieval and mining over the dataset.
This paper explores the approach of NoSql query design and analysis of different datasets, particularly a proteome-protein dataset over a renowned graph database, Neo4j. The mode of experiments involve the evaluation of NoSql query execution on datasets vary in the number of nodes and relationships between them. It also emphasises the process of mining large graphs with meaningful queries based on a NoSql Query language called Cypher.
17.Chronic kidney disease analysis using data mining classification techniques
Data mining has been a current trend for attaining diagnostic results. Huge amount of unmined data is collected by the healthcare industry in order to discover hidden information for effective diagnosis and decision making. Data mining is the process of extracting hidden information from massive dataset, categorizing valid and unique patterns in data . There are many data mining techniques like clustering, classification, association analysis, regression etc.
The objective of our paper is to predict Chronic Kidney Disease(CKD) using classification techniques like Naive Bayes and Artificial Neural Network(ANN).The experimental results implemented in Rapidminer tool show that Naive Bayes produce more accurate results than Artificial Neural Network.
CHRONIC KIDNEY DISEASE ANALYSIS USING DATA MINING CLASSIFICATION TECHNIQUES
18.Gene Selection by Sample Classification using k Nearest Neighbor and Meta-heuristic Algorithms
Advent in microarray technology enables the researchers of computational biology to apply various bioinformatics paradigms on gene expression data. But microarray gene expression data, obtained as a matrix has much larger number of genes as rows than number of samples (columns representing time points / disease states) which makes many bioinformatics jobs critical. In this direction a subset of genes are selected from the large noisy dataset so that their features are distinguishable between different types of samples (normal / diseased).
Here, in this paper, the gene selection process is performed by sample classification using k Nearest Neighbor (k-NN) method. Comparing normal and preeclampsia affected microarray gene expression samples, collected from human placentas; we have selected a set of genes which may be termed as critical for a disease named Preeclampsia, a common complication during pregnancy causing hypertension and proteinuria. Both the normal and diseased dataset contain 25000 genes (rows) having 75 samples (columns) and we have selected 30 genes as disease-critical genes.
We have applied two metaheuristic algorithms, namely, Simulated Annealing (SA) and Particle Swarm Optimization (PSO). Sample classification of normal and preeclampsia shows high fitness (number of samples properly classified). Here, out of 150 (75 normal + 75 diseased) samples, 80-90 samples are properly classified. The number of samples properly classified, denotes the fitness of a solution. So, achieved solution here is of good quality. In our experiments, PSO outperformed SA in respect of best fitness and SA defeated PSO in average fitness.
19.Outlier detection techniques for network attacks.
Outlier detection has been used for centuries to detect, where appropriate, remove anomalous observations from data. Outliers arise due to mechanical faults, changes in system behavior, fraudulent behavior, human error, instrument error or simply through natural deviations in populations. These anomalous patterns are usually called outliers, noise, anomalies, exceptions, faults, defects, errors in different application domains.
The proposed method analyses the NSL-KDD dataset of various clustering algorithms like KNN, wards and NN to find outliers from the each resulting clusters and then apply different outlier detection techniques which are of distance based, density based, soft computing based to the resultant dataset by using data mining WEKA tool. And finally the results are analyzed for the proposed method which performs with high accuracy in less time complexity.
20.Distributed Storage Design for Encrypted Network Intrusion Record (DSeNiR)
DSeNiR is proposed in this project in order to manage the encrypted network intrusion on a cloud storage Hbase and Hadoop are Utilized in this work. The objective is to provide an API for any Ni system to upload/download the encrypted network intrusion data from a cloud storage. The DSeNiR resolve the name node memory issues of HDFS. When storing a lot of small files by classifying the encrypted network intrusion data into small and large files. The small files will be handled by HBase schema that is proposed in this work. The memory consumption and the processing time of the proposed DSeNiR are evaluated using real data sets collected from various network intrusions.
21.Distributed Storage Design for Encrypted Network Intrusion Record (DSeNiR)
DSeNiR is proposed in this project in order to manage the encrypted network intrusion on a cloud storage Hbase and Hadoop are Utilized in this work. The objective is to provide an API for any Ni system to upload/download the encrypted network intrusion data from a cloud storage. The DSeNiR resolve the name node memory issues of HDFS. When storing a lot of small files by classifying the encrypted network intrusion data into small and large files. The small files will be handled by HBase schema that is proposed in this work. The memory consumption and the processing time of the proposed DSeNiR are evaluated using real data sets collected from various network intrusions.
22.Time Table Generation
A college timetable is a temporal arrangement of a set of lectures and classrooms in which all given constraints are satisfied. Creating such timetables manually is complex and time-consuming process. By automating this process with computer assisted timetable generator can save a lot of precious time of administrators who are involved in creating and managing course timetables. Since every college has its own timetabling problem, the commercially available software packages may not suit the need of every college.
Hence we have developed practical approach for building lecture course timetabling system, which can be customized to fit to any colleges timetabling problem.This project introduces a practical timetabling algorithm capable of taking care of both strong and weak constraints effectively, used in an automated timetabling system. So that each teacher and student can view their timetable once they are finalized for a given semester but they can’t edit them.
23.Invoice Generator
Generation of an Invoice bill of selected products from a different websites and generates the bill through PDF format and forwards the bill to gmail.
24.Faculty Feedback And Growth Analyser
The main aim and objective was to plan and Software application for any domain. We have to apply the best software engineering practice for web application. As a Software application developer I was asked to developed an “Faculty Feedback System” using Core Java. “Faculty Feedback System” This system is generally used by four kinds of users Student, Faculty, Head of departments, Admin.
The application should evaluate the answers given by the students based on the feedback (which will be given by a no. 1 – 5) and grade has to be generated to all the staff members of a particular department. These feedback report was checked by the hod's. He can view overall grades and view the grades obtained to the lecturers and give this report to the principal and he can give counseling to the college staff. “By using this online system we make it better and quick way.”
25.A Big Data Clustering Algorithm for Mitigating the Risk of Customer Churn
As market competition intensifies, customer churn management is increasingly becoming an important means of competitive advantage for companies. However, when dealing with big data in the industry, existing churn prediction models cannot work very well. In addition, decision makers are always faced with imprecise operations management. In response to these difficulties, a new clustering algorithm called Semantic Driven Subtractive Clustering Method (SDSCM) is proposed.
Experimental results indicate that SDSCM has stronger clustering semantic strength than Subtractive Clustering Method (SCM) and fuzzy c-means (FCM). Then a parallel SDSCM algorithm is implemented through a Hadoop MapReduce framework. In the case study, the proposed parallel SDSCM algorithm enjoys a fast running speed when compared with the other methods. Furthermore, We provide some marketing strategies in accordance with the clustering results, and a simplified marketing activity is simulated to ensure profit maximization.
26.Suspect Verification Based on Indian Law System
This project focuses on predicting the suspect of any crime by using various data and information stored on cloud database such as background of person involved in crimes, evidences collected from crime scenes. Based on the facts and data, our law system will punish the prime suspect. This system provides an easy way of finding the respective lawyers to both accused and victim, so that they will get proper judgements from our law. In other words, we can say we are developing a system which will provide an easy platform for investigating departments in finding the prime suspect who finds guilty in a particular crime.
27.Mining Partially-Ordered Sequential Rules Common to Multiple Sequences
Sequential rule mining is an important data mining problem with multiple applications. An important limitation of algorithms for mining sequential rules common to multiple sequences is that rules are very specific and therefore many similar rules may represent the same situation. This can cause three major problems: (1) similar rules can be rated quite differently, (2) rules may not be found because they are individually considered uninteresting, and (3) rules that are too specific are less likely to be used for making predictions.
To address these issues, we explore the idea of mining “partially-ordered sequential rules” (POSR), a more general form of sequential rules such that items in the antecedent and the consequent of each rule are unordered. To mine POSR, we propose the RuleGrowth algorithm, which is efficient and easily extendable. In particular, we present an extension (TRuleGrowth) that accepts a sliding-window constraint to find rules occurring within a maximum amount of time.
A performance study with four real-life datasets show that RuleGrowth and TRuleGrowth have excellent performance and scalability compared to baseline algorithms and that the number of rules discovered can be several orders of magnitude smaller when the sliding-window constraint is applied. Furthermore, we also report results from a real application showing that POSR can provide a much higher prediction accuracy than regular sequential rules for sequence prediction.
28.Mining High Utility Patterns in One Phase without Generating Candidates
Utility mining is a new development of data mining technology. Among utility mining problems, utility mining with the itemset share framework is a hard one as no anti-monotonicity property holds with the interestingness measure. Prior works on this problem all employ a two-phase, candidate generation approach with one exception that is however inefficient and not scalable with large databases. The two-phase approach suffers from scalability issue due to the huge number of candidates.
This paper proposes a novel algorithm that finds high utility patterns in a single phase without generating candidates. The novelties lie in a high utility pattern growth approach, a lookahead strategy, and a linear data structure. Concretely, our pattern growth approach is to search a reverse set enumeration tree and to prune search space by utility upper bounding. We also look ahead to identify high utility patterns without enumeration by a closure property and a singleton property.
Our linear data structure enables us to compute a tight bound for powerful pruning and to directly identify high utility patterns in an efficient and scalable way, which targets the root cause with prior algorithms. Extensive experiments on sparse and dense, synthetic and real world data suggest that our algorithm is up to 1 to 3 orders of magnitude more efficient and is more scalable than the state-of-the-art algorithms.
29.TASC:Topic-Adaptive Sentiment Classification on Dynamic Tweets
Sentiment classification is a topic-sensitive task, i.e., a classifier trained from one topic will perform worse on another. This is especially a problem for the tweets sentiment analysis. Since the topics in Twitter are very diverse, it is impossible to train a universal classifier for all topics. Moreover, compared to product review, Twitter lacks data labeling and a rating mechanism to acquire sentiment labels. The extremely sparse text of tweets also brings down the performance of a sentiment classifier.
In this paper, we propose a semi-supervised topic-adaptive sentiment classification (TASC) model, which starts with a classifier built on common features and mixed labeled data from various topics. It minimizes the hinge loss to adapt to unlabeled data and features including topic-related sentiment words, authors’ sentiments and sentiment connections derived from “@” mentions of tweets, named as topic-adaptive features. Text and non-text features are extracted and naturally split into two views for co-training. The TASC learning algorithm updates topic-adaptive features based on the collaborative selection of unlabeled data, which in turn helps to select more reliable tweets to boost the performance.
We also design the adapting model along a timeline (TASC-t) for dynamic tweets. An experiment on 6 topics from published tweet corpuses demonstrates that TASC outperforms other well-known supervised and ensemble classifiers. It also beats those semi-supervised learning methods without feature adaption. Meanwhile, TASC-t can also achieve impressive accuracy and F-score. Finally, with timeline visualization of “river” graph, people can intuitively grasp the ups and downs of sentiments’ evolvement, and the intensity by color gradation.
30.A Compendium for Prediction of Success of a Movie Based Upon Different Factors
The success of a movie is uncertain but it is no secret that it is dependent to a large extent upon the level of promotion and also upon the ratings received by the major movie critics. Time and money are valuable to the general audience and hence, they refer to the leading critics when making a decision about whether to watch a particular movie or not. Over 1000 movies on an average are produced per year. Therefore, in order to make the movie profitable, it becomes a matter of concern that the movie succeeds.
Due to the low success rate, models and mechanisms to predict reliably the ranking and or box office collections of a movie can risk the business significantly. The current predictive models that are available are based on various factors for assessment of the movie. These include the typical factors such as cast, producer, director etc. or the social factors in form of response of the society on various online platforms. Various stakeholders such as actors, financiers, directors etc. can use these predictions to make more informed decisions.
31.Canopy Clustering Based K Strange Point Detection.
A Theoretical Comparison of Job scheduling Algorithms in Cloud Computing Environment Cloud computing is a dynamic, scalable and pay per-use distributed computing model empowering designers to convey applications amid job designation and storage distribution. Cloud computing encourages to impart a pool of virtualized computer resource empowering designers to convey applications amid job designation and storage distribution. The cloud computing mainly aims to give proficient access to remote and geographically distributed resources.
As cloud technology is evolving day by day and confronts numerous challenges, one of them being uncovered is scheduling. Scheduling is basically a set of constructs constructed to have a controlling hand over the order of work to be performed by a computer system. Algorithms are vital to schedule the jobs for execution. Job scheduling algorithms is one of the most challenging hypothetical problems in the cloud computing domain area. Numerous deep investigations have been carried out in the domain of job scheduling of cloud computing.
This paper intends to present the performance comparison analysis of various pre-existing job scheduling algorithms considering various parameters. This paper discusses about cloud computing and its constructs in section (i). In section (ii) job scheduling concept in cloud computing has been elaborated. In section (iii) existing algorithms for job scheduling are discussed, and are compared in a tabulated form with respect to various parameters and lastly section (iv) concludes the paper giving brief summary of the work.
32.Automated Discovery of Small Business Domain Knowledge Using Web Crawling and Data Mining
It has become an era where everything is on the web with ever more chances of data utilization on the web. Still, there are obstacles to make the use of the web efficiently. With too much information, Internet users have often come across information that are not relevant for their use. On top of that, until recently, most of web content have not contained semantic information, posing difficulties for mechanical analysis. The Semantic Web emerged as a way to tackle those poor qualities of the web.
Adopting formal languages such as RDF or OWL, the semantic web has made the Internet become more highly available for computer-based analysis. In this study, what we aimed at is building a small business knowledge base to provide useful information for small business owners for their marketing strategies or dynamic QA systems for their restaurant recommendation services.
The knowledge base was built according to the concept of the Semantic Web. To build the knowledge base, first, it is needed to conduct web crawling from different web sources including social media. However, the crawled data typically come in informal and do not have any semantic information. So we devised text mining techniques to catch useful information from them and generate formal knowledge for the knowledge base.
33.Comparative Analysis of K-Means and Fuzzy C Menas on Thiroid Disease
To recognize in vast restorative and variation groups with unstructured information is dependably a major test furthermore hazard component to exhibit outside world in an organized configuration. To overcome dependably the information ought to be stemmed and sorted in grouped parts. K-means is utilized as a part of the primary methodology of our as DDC. By taking the mean estimation of age and the groups will be encircled. Be that as it may, the groups are just mean based arrangement so we propose another methodology after K-Means based manufactured FFM.
Taken after by that arbitrary markers set to get the achievable consequences of classification furthermore recurrence of appearance regarding allocated irregular scope of interesting qualities to every last existing mix tuple. To accomplish the wanted arrangement of activity we propose another methodology recognized bunching and attainable recurrence with extraordinary result for each procedure. These successions are trailed by non-standard pre-handling like self-cleaning of information and stemming.
The pre-handling is finished by semi fluffy system. To accomplish these things of procedure we propose another calculation called DDC (unmistakable relocation for grouping) and UTOF (Unique recurrence result in expandable information. This procedure is absolutely on extensive therapeutic information which is constantly expandable with different new infections. The above calculation takes after a specific new system called doable fluffy mining (FFM) strategy
34.The Classification Techniques on Medical Data to Predict Heart Disease
Analysis of therapeutic information is very test in context of incremental development of properties and different parameters. Once the information is gathering there is specific farthest point to wind up in getting the information as tuples or ascertaining the recurrence of the combinational credits concerning age, ailment, sexual orientation. The most compelling motivation is to push the mysterious maladies in examination. In substantial information related information spotting of the fancied infection information is excessively muddled.
So we utilize KNN with Euclidean separation component and choice tree with ordinary and upgraded model concerning given characteristics. In KNN Euclidean separation produced for all tuples and rank will be accommodate new characterization of new set and result created in light of k worth as closest neighbors. Be that as it may, for examination is between both above said as for investigation of time multifaceted nature for order. The principle characterization is done on tremendous and element patch information. So the fundamental arrangement is done on KNN methodology and immediate arrangement trees make up by utilizing NAE approach (typical and improved choice tree structures)
35.Improved Techniques for Sentiment Analysis on Social Network.
Sentiment analysis (also known as opinion mining) refers to the use of natural language processing, text analysis and computational linguistics to identify and extract subjective information in source materials. Sentiment analysis is widely applied to reviews and social media for a variety of applications, ranging from marketing to customer service.Generally speaking, sentiment analysis aims to determine the attitude of a speaker or a writer with respect to some topic or the overall contextual polarity of a document.
A basic task in sentiment analysis is classifying the polarity of a given text at the document, sentence, or feature/aspect level whether the expressed opinion in a document, a sentence or an entity feature/aspect is positive, negative, or neutral. Advanced, "beyond polarity" sentiment classification looks, for instance, at emotional states such as "angry", "sad", and "happy".A different method for determining sentiment is the use of a scaling system whereby words commonly associated with having a negative, neutral or positive sentiment with them are given an associated number on a -10 to +10 scale (most negative up to most positive). This makes it possible to adjust the sentiment of a given term relative to its environment (usually on the level of the sentence).
When a piece of unstructured text is analyzed using natural language processing, each concept in the specified environment is given a score based on the way sentiment words relate to the concept and its associated score. This allows movement to a more sophisticated understanding of sentiment, because it is now possible to adjust the sentiment value of a concept relative to modifications that may surround it. Words, for example, that intensify, relax or negate the sentiment expressed by the concept can affect its score. Alternatively, texts can be given a positive and negative sentiment strength score if the goal is to determine the sentiment in a text rather than the overall polarity and strength of the text
Project Overview
After acquiring the twitter data and by taking the dictionaries(+ve and -ve) analysis will happen to prediction and +ve and -ve frequency for the recommendations.
System Requirement
Hardware Requirement
Processor - Dual Core
Speed - 1.1 G Hz
RAM - 512 MB (min)
Hard - 20 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Software Requirement
Operating System : Windows xp,7,8
Front End : Java 7
Technology : swings, core java
IDE : Netbeans
36.Enriched Content Mining For Web Applications
In recent years, it has been witnessed that the ever-interesting and upcoming publishing medium is the World Wide Web. Much of the web content is unstructured so gathering and making sense of such data is very tedious. Web servers worldwide generate a vast amount of information on web users’ browsing activities.Several researchers have studied these so-called web access log data to better understand and characterize web users. Data can be enriched with information about the content of visited pages and the origin (e.g., geographic, organizational) of the requests.
The goal of this project is to analyze user behavior by mining enriched web access log data. The several web usage mining methods for extracting useful features is discussed and employ all these techniques to cluster the users of the domain to study their behaviors comprehensively. The contributions of this thesis are a data enrichment that is content and origin based and a treelike visualization of frequent navigational sequences.
This visualization allows for an easily interpretable tree-like view of patterns with highlighted relevant information. The results of this project can be applied on diverse purposes, including marketing, web content advising, (re- )structuring of web sites and several other E-business processes, like recommendation and advertiser systems. It also rank the best relevant documents based on Top K query for effective and efficient data retrieval system. It filters the web documents by providing the relevant content in the search engine result page (SERP).
37.Text Mining-Supported Information Extraction
Information extraction (IE) and knowledge discovery in databases (KDD) are both useful approaches for discovering information in textual corpora, but they have some deficiencies. Information extraction can identify relevant subsequences of text, but is usually unaware of emerging, previously unknown knowledge and regularities in a text and thus cannot form new facts or new hypotheses.
Complementary to information extraction, emerging data mining methods and techniques promise to overcome the deficiencies of information extraction. This research work combines the benefits of both approaches by integrating data mining and information extraction methods. The aim is to provide a new high-quality information extraction methodology and, at the same time, to improve the performance of the underlying extraction system.
Consequently, the new methodology should shorten the life cycle of information extraction engineering because information predicted in early extraction phases can be used in further extraction steps, and the extraction rules developed require fewer arduous test-and-debug iterations. Effectiveness and applicability are validated by processing online documents from the areas of eHealth and eRecruitment.
38.Dynamic Query Forms for Database Queries
Modern scientific databases and web databases maintain large and heterogeneous data. These real-world databases contain hundreds or even thousands of relations and attributes. Traditional predefined query forms are not able to satisfy various ad-hoc queries from users on those databases. This paper proposes DQF, a novel database query form interface, which is able to dynamically generate query forms. The essence of DQF is to capture a user’s preference and rank query form components, assisting him/her in making decisions.
The generation of a query form is an iterative process and is guided by the user. At each iteration, the system automatically generates ranking lists of form components and the user then adds the desired form components into the query form. The ranking of form components is based on the captured user preference. A user can also fill the query form and submit queries to view the query result at each iteration.
In this way, a query form could be dynamically refined until the user is satisfied with the query results. We utilize the expected F-measure for measuring the goodness of a query form. A probabilistic model is developed for estimating the goodness of a query form in DQF. Our experimental evaluation and user study demonstrate the effectiveness and efficiency of the system.
39.Secure Data Mining in Cloud using Homomorphic Encryption
With the advancement in technology, industry, ecommerce and research a large amount of complex and pervasive digital data is being generated which is increasing at an exponential rate and often termed as big data. Traditional Data Storage systems are not able to handle Big Data and also analyzing the Big Data becomes a challenge and thus it cannot be handled by traditional analytic tools.
Cloud Computing can resolve the problem of handling, storage and analyzing the Big Data as it distributes the big data within the cloudlets.No doubt, Cloud Computing is the best answer available to the problem of Big Data storage and its analyses but having said that, there is always a potential risk to the security of Big Data storage in Cloud Computing, which needs to be addressed. Data Privacy is one of the major issues while storing the Big Data in a Cloud environment.
Data Mining based attacks, a major threat to the data, allows an adversary or an unauthorized user to infer valuable and sensitive information by analyzing the results generated from computation performed on the raw data. This thesis proposes a secure k-means data mining approach assuming the data to be distributed among different hosts preserving the privacy of the data. The approach is able to maintain the correctness and validity of the existing k-means to generate the final results even in the distributed environment.
40.RuleGrowth: Mining Sequential Rules Common to Several Sequences by Pattern-Growth
Mining sequential rules from large databases is an important topic in data mining fields with wide applications. Most of the relevant studies focused on finding sequential rules appearing in a single sequence of events and the mining task dealing with multiple sequences were far less explored. In this paper, we present RuleGrowth, a novel algorithm for mining sequential rules common to several sequences.
Unlike other algorithms, RuleGrowth uses a pattern-growth approach for discovering sequential rules such that it can be much more efficient and scalable. We present a comparison of Rule Growth’s performance with current algorithms for three public datasets. The experimental results show that RuleGrowth clearly outperforms current algorithms for all three datasets under low support and confidence threshold and has a much better scalability.
41.Secure Mining of Association Rules in Horizontally Distributed Databases
We propose a protocol for secure mining of association rules in horizontally distributed databases. The current leading protocol is that of Kantarcioglu and Clifton [18]. Our protocol, like theirs, is based on the Fast Distributed Mining (FDM) algorithm of Cheung et al. [8], which is an unsecured distributed version of the Apriori algorithm.
The main ingredients in our protocol are two novel secure multi-party algorithms—one that computes the union of private subsets that each of the interacting players hold, and another that tests the inclusion of an element held by one player in a subset held by another. Our protocol offers enhanced privacy with respect to the protocol in [18]. In addition, it is simpler and is significantly more efficient in terms of communication rounds, communication cost and computational cost
42.A Privacy Leakage Upper-Bound Constraint Based Approach for Cost-Effective Privacy Preserving of Intermediate Datasets In cloud
Cloud computing provides massive computation power and storage capacity which enable users to deploy computation and data intensive applications without infrastructure investment. Along the processing of such applications, a large volume of intermediate datasets will be generated, and often stored to save the cost of re-computing them. However, preserving the privacy of intermediate datasets becomes a challenging problem because adversaries may recover privacy-sensitive information by analyzing multiple intermediate datasets.
Encrypting ALL datasets in cloud is widely adopted in existing approaches to address this challenge. But we argue that encrypting all intermediate datasets are neither efficient nor cost-effective because it is very time consuming and costly for data-intensive applications to en/decrypt datasets frequently while performing any operation on them.
In this paper, we propose a novel upper-bound privacy leakage constraint based approach to identify which intermediate datasets need to be encrypted and which do not, so that privacy-preserving cost can be saved while the privacy requirements of data holders can still be satisfied. Evaluation results demonstrate that the privacy-preserving cost of intermediate datasets can be significantly reduced with our approach over existing ones where all datasets are encrypted.
43.Automatic Medical Disease Treatment System Using Datamining
In our proposed system is identifying reliable information in the medical domain stand as building blocks for a healthcare system that is up-to date with the latest discoveries. By using the tools such as NLP, ML techniques. In this research, focus on diseases and treatment information, and the relation that exists between these two entities.
The main goal of this research is to identify the disease name with the symptoms specified and extract the sentence from the article and get the Relation that exists between Disease- Treatment and classify the information into cure, prevent, side effect to the user.This electronic document is a “live” template. The various components of your paper [title, text, heads, etc.] are already defined on the style sheet, as illustrated by the portions given in this document.
44.Efficient Algorithms for Mining High Utility Itemsets from Transactional Databases
Mining high utility itemsets from a transactional database refers to the discovery of itemsets with high utility like profits. Although a number of relevant algorithms have been proposed in recent years, they incur the problem of producing a large number of candidate itemsets for high utility itemsets. Such a large number of candidate itemsets degrades the mining performance in terms of execution time and space requirement.
The situation may become worse when the database contains lots of long transactions or long high utility itemsets. In this paper, we propose two algorithms, namely utility pattern growth (UP-Growth) and UP-Growth+, for mining high utility itemsets with a set of effective strategies for pruning candidate itemsets. The information of high utility itemsets is maintained in a tree-based data structure named utility pattern tree (UP-Tree) such that candidate itemsets can be generated efficiently with only two scans of database.
The performance of UP-Growth and UP-Growth+ is compared with the state-of-the-art algorithms on many types of both real and synthetic data sets. Experimental results show that the proposed algorithms, especially UPGrowth+, not only reduce the number of candidates effectively but also outperform other algorithms substantially in terms of runtime,especially when databases contain lots of long transactions.
45.Automatic Itinerary Planning for Traveling Services
Creating an efficient and economic trip plan is the most annoying job for a backpack traveler. Although travel agency can provide some predefined itineraries, they are not tailored for each specific customer. Previous efforts address the problem by providing an automatic itinerary planning service, which organizes the points-of-interests (POIs) into a customized itinerary. Because the search space of all possible itineraries is too costly to fully explore, to simplify the complexity, most work assume that user’s trip is limited to some important POIs and will complete within one day.
To address the above limitation, in this paper, we design a more general itinerary planning service, which generates multiday itineraries for the users. In our service, all POIs are considered and ranked based on the users’ preference. The problem of searching the optimal itinerary is a team orienteering problem (TOP), a well-known NP-complete problem.
To reduce the processing cost, a two-stage planning scheme is proposed. In its preprocessing stage, single-day itineraries are precomputed via the MapReduce jobs. In its online stage, an approximate search algorithm is used to combine the single day itineraries. In this way, we transfer the TOP problem with no polynomial approximation into another NP-complete problem (set-packing problem) with good approximate algorithms. Experiments on real data sets show that our approach can generate high-quality itineraries efficiently.
46.Identifying Features in Opinion Mining via Intrinsic and Extrinsic Domain Relevance
The vast majority of existing approaches to opinion feature extraction rely on mining patterns only from a single review corpus, ignoring the nontrivial disparities in word distributional characteristics of opinion features across different corpora. In this paper, we propose a novel method to identify opinion features from online reviews by exploiting the difference in opinion feature statistics across two corpora, one domain-specific corpus (i.e., the given review corpus) and one domain-independent corpus (i.e., the contrasting corpus).
We capture this disparity via a measure called domain relevance (DR), which characterizes the relevance of a term to a text collection. We first extract a list of candidate opinion features from the domain review corpus by defining a set of syntactic dependence rules. For each extracted candidate feature, we then estimate its intrinsic-domain relevance (IDR) and extrinsic-domain relevance (EDR) scores on the domain-dependent and domain-independent corpora, respectively.
Candidate features that are less generic (EDR score less than a threshold) and more domain-specific (IDR score greater than another threshold) are then confirmed as opinion features. We call this interval thresholding approach the intrinsic and extrinsic domain relevance (IEDR) criterion. Experimental results on two real-world review domains show the proposed IEDR approach to outperform several other well-established methods in identifying opinion features.
47.Keyword Query Routing
Keyword search is an intuitive paradigm for searching linked data sources on the web. We propose to route keywords only to relevant sources to reduce the high cost of processing keyword search queries over all sources. We propose a novel method for computing top-k routing plans based on their potentials to contain results for a given keyword query. We employ a keyword-element relationship summary that compactly represents relationships between keywords and the data elements mentioning them.
A multilevel scoring mechanism is proposed for computing the relevance of routing plans based on scores at the level of keywords, data elements, element sets, and subgraphs that connect these elements. Experiments carried out using 150 publicly available sources on the web showed that valid plans (precision@1 of 0.92) that are highly relevant (mean reciprocal rank of 0.89) can be computed in 1 second on average on a single PC. Further, we show routing greatly helps to improve the performance of keyword search, without compromising its result quality.
48.The Role of Apriori Algorithm for Finding the Association Rules in Data Mining
Now a day's Data mining has a lot of e-Commerce applications. The key problem is how to find useful hidden patterns for better business applications in the retail sector. For the solution of these problems, The Apriori algorithm is one of the most popular data mining approach for finding frequent item sets from a transaction dataset and derive association rules. Rules are the discovered knowledge from the database.
Finding frequent item set (item sets with frequency larger than or equal to a user specified minimum support) is not trivial because of its combinatorial explosion. Once frequent item sets are obtained, it is straightforward to generate association rules with confidence larger than or equal to a user specified minimum confidence. The paper illustrating apriori algorithm on simulated database and finds the association rules on different confidence value.
49.Efficient Mining of Both Positive and Negative Association Rules
This paper presents an efficient method for mining both positive and negative association rules in databases. The method extends traditional associations to include association rules of forms A ) :B, :A) B, and :A ) :B, which indicate negative associations between itemsets. With a pruning strategy and an interestingness measure, our method scales to large databases. The method has been evaluated using both synthetic and real-world databases, and our experimental results demonstrate its effectiveness and efficiency. Categories and Subject Descriptors: I.2.6
Leave Your Comment Here